L55_你又在绘制新的航线了吗

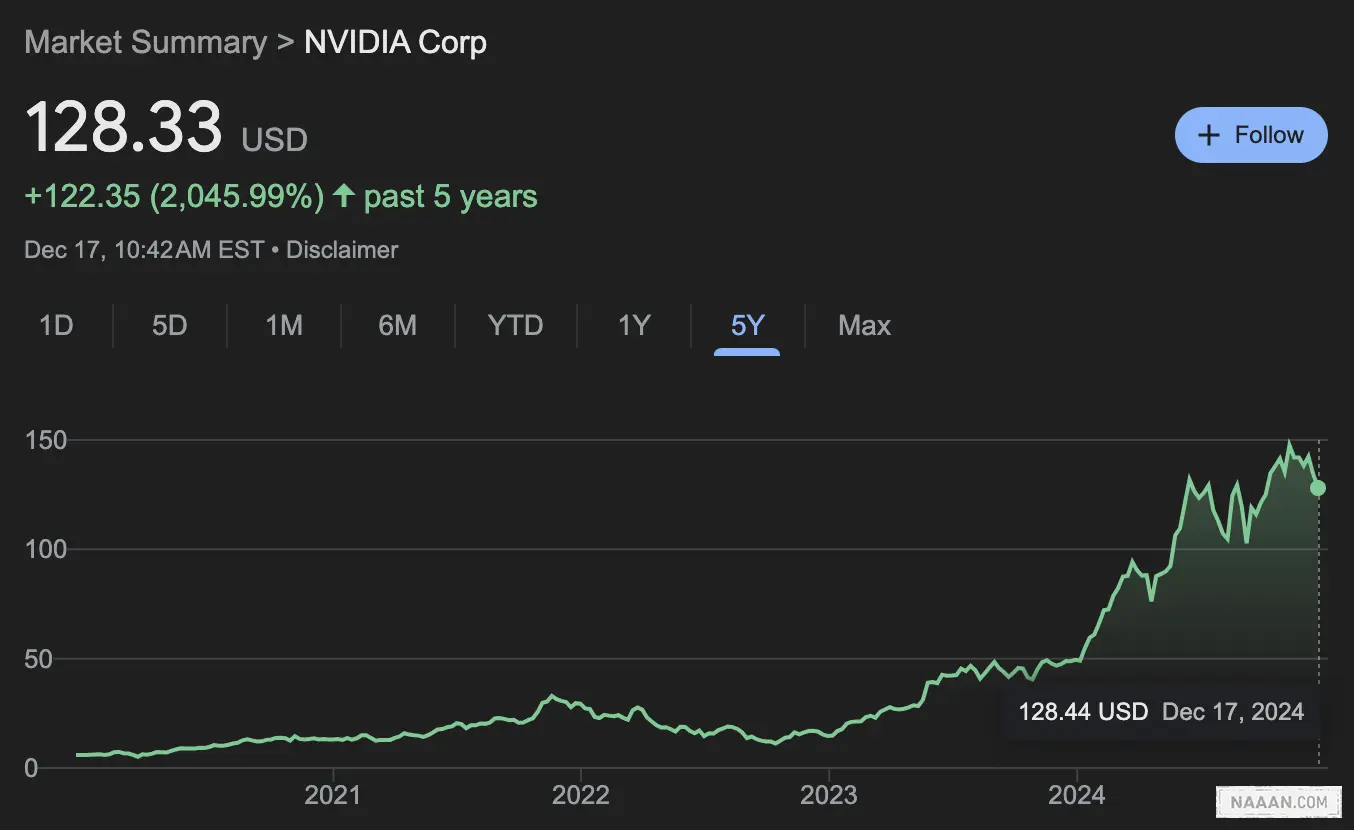
在模型的预训练阶段,Scaling Laws 的效果确实有所放缓,但在后训练和多模态模型的场景下,数据的 Scaling 仍然有显著的提升空间。有研究员从 Scaling 的原理出发,认为模型在第一阶段的性能提升依赖于从小模型到大模型的「非线性到线性」转变。然而,当模型已经足够大时,这种转变的效果难以预测,预训练的效果可能会趋于瓶颈。尽管如此,研究员们并不认为预训练的 Scaling Laws 已经完全结束,尤其是在多模态模型中,数据的 Scaling Laws 仍有许多未被探索的领域。目前,许多公司选择大力投入后训练,主要是出于性价比的考虑。
干货分享:一场OpenAI、NVIDIA、Anthropic、Google研究员的新年硬核聊天
闫俊杰认为,用户数量等指标并不是 AI 竞争的核心。他强调,不应使用移动互联网时代的产品方法论来思考 AI 大模型产品。他指出,中国大部分公司,无论是创业公司还是大厂,仍然在使用推荐系统的方法来开发大模型产品。然而,AI 大模型与产品的关系是:更好的模型可以带来更好的应用,但更好的应用和更多的用户并不会直接导致模型的改进。例如,ChatGPT 的日活跃用户数(DAU)是 Claude 的 50 到 100 倍,但两者的模型性能却相差无几。