GPT 的基本原理
AIGC 突然火了?
ChatGPT 3.5 只引入了对话能力,但是立马就引爆了整个非技术圈。最显而易见,无论是天猫精灵、小爱同学还是 Alexa,相较于 ChatGPT 都像是上个时代产物。人们在面对 AIGC 时,除了对技术变革的惊讶,还有就是对于被替代的惶恐,以及对于未来风口的追赶。
我对这 6 年前的技术感到十分的好奇,所以想看一下 AIGC 中 GPT 的算法模型是如何工作的。
神经网络
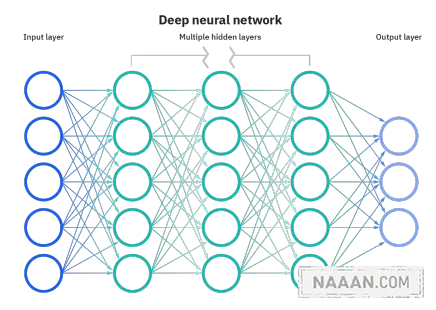
首先需要了解的是神经网络(Artificial Neural Networks),这是一种计算机程序或算法,其设计灵感源自于生物神经系统的工作原理。它由大量 相互连接的节点(也称为神经元)组成,这些节点模拟人脑中的神经元之间的联系。
具体来说,神经网络通常包括 输入层、隐藏层和输出层。输入层接收原始数据,并将其传递给隐藏层。隐藏层通过加权求和和激活函数的处理,将输入信号转化为更高层次的抽象特征表示,并传递给输出层。输出层根据目标任务的不同,可能采用不同的激活函数和损失函数来实现分类、回归、聚类等目标。
RNN (Recurrent Neural Network)
我们知道人类并 不是从零开始思考东西,就像你读这篇文章的时候,你对每个字的理解都是建立在前几个字上面。你读完每个字后并不是直接丢弃然后又从零开始读下一个字,因为你的 思想是具有持续性 的,很多东西你要通过上下文才能理解。
然而传统的神经网络并不能做到持续记忆理解这一点,这是传统神经网络的主要缺点。举个例子,你打算使用传统的神经网络去对电影里每个时间点发生的事情进行分类的时候,传统的神经网络不能使用前一个事件去推理下一个事件。
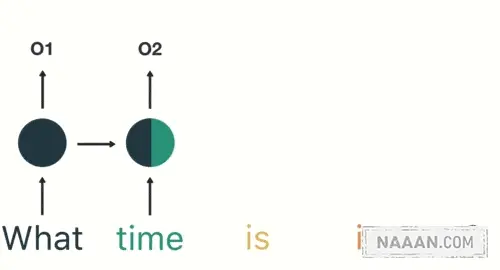
RNN 算法模型能够通过记忆机制来捕捉序列中的上下文信息。例如下方「What time is it?」的单词会从前往后一直向后传递。
Attention 机制

RNN 的缺点也比较明显,通过上面的例子,我们已经发现,短期的记忆影响较大(如橙色区域),但是长期的记忆影响就很小(如黑色和绿色区域),这就是 RNN 存在的短期记忆问题。
- RNN 有短期记忆问题,无法处理很长的输入序列(梯度消失问题)
由于 RNN 的短期记忆问题,后来又出现了基于 RNN 的优化演算法,比如 LSTM(Long short-term memory),GRU(Gated Recurrent Unit)。本质都是为了将重要的信息透传,但是这个算法只能减缓梯度消失问题,不能解决梯度消失问题。
我们看下方的这个图,告诉我第一眼看到的东西:

Attention 机制很像人类看图片的逻辑,当我们看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。
在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。下图红色的区域就是被挑出来的重点。

Transformer
Transformer 模型通过引入「自注意力机制 self-attention」解决处理长序列化输入时可能存在的梯度消失、梯度爆炸或是长度限制问题。此外,自注意力机制还能大幅提升模型训练的速度。
Transformer 把序列中的所有单词或者符号并行处理,同时借助自注意力机制对句子中所有单词之间的关系直接进行建模,而无需考虑各自的位置。具体而言,Transformer 会将该单词与句子中的其它单词一一对比,并得出这些单词的注意力分数。注意力分数决定其它单词对给定词汇的语义影响。之后,注意力分数用作所有单词表征的平均权重,这些表征输入全连接网络,生成新表征。

使用 Transformer 模型进行翻译工作的示意图(来源 Google)
Transformer 在 2017 年由 Google 在题为《Attention Is All You Need》的论文中提出
GPT(Generative Pre-trained Transformers)
终于到了重点。

GPT(Generative Pre-trained Transformers)是一种基于 Transformer 模型的自然语言处理模型,该模型采用了预训练加微调的方法,先在大规模的语料库上进行预训练,然后在特定任务上进行微调。该模型于 2018 年 6 月由 OpenAI 首次提出。
GPT 模型的预训练采用了无监督学习的方式(注:在预训练阶段基于自注意力机制可以不依赖结构化打标数据,GPT 可学习的语料库相比其他模型有着数量级上的差异),即在大规模语料库上进行自回归训练。它使用了 Transformer 模型中的自注意力机制和前馈神经网络,以及多头注意力机制等技术来学习输入序列的表示。在预训练过程中,GPT 模型尝试预测下一个单词,通过这种方式逐步学习语言的规律和结构,从而得到对输入序列的深层次表示。
举个例子,假设我们有一个句子:「The cat is lying on the ___」. 在 MLM 模型中,我们可以将其中的一个单词「mat」屏蔽掉,并让该模型来预测正确的单词。在这个句子中,上下文信息对于预测正确的单词至关重要。如果之前的上下文提到了「floor」,那么预测的单词可能是「floor」。如果之前的上下文提到了「bed」,那么预测的单词可能是「bed」。
在微调阶段,GPT 模型通常需要进行一定程度的修改以适应特定任务(注:因此衍生出各类 GPT,最出名的是 ChatGPT)。例如,对于文本生成任务,可以在 GPT 模型上添加一个分类器来预测下一个单词;对于问答任务,可以在 GPT 模型的输出上添加额外的分类器来预测答案。
我们以回答「讲一个「行权」和「A+」的故事」为例来说明 GPT 模型的工作方式。
首先,我们需要将这个问题输入到 GPT 模型中。GPT 模型会根据预训练时学习到的知识结构,在语言模型的基础上生成一个开放式的自然语言文本序列。
接下来,GPT 模型会尝试从已有的文本数据中生成一个能够贴合问题的连贯文本片段,该片段包含与「行权」和「A+」相关的故事线索。
最后,GPT 模型会输出一个完整的、通顺连贯的故事文本,该文本描述了「行权」和「A+」之间的某种联系或互动。这个故事的内容可能是虚构的,也可能基于真实的历史事件。