L92_技术真实的金融幻觉

上周,杨振宁先生逝世的消息传来,令人深感痛惜。
我所就读的研究生院校,正是杨先生职业生涯最后工作的地方。学校对杨先生极为敬重,据我所知,即便先生早已荣休,学校也一直为他保留着那间办公室。
当他离世的讯息发布后,在留学生群体中引起了巨大震动。消息传出的第一时间,便有中国留学生在深夜时分,自发赶赴杨先生的办公室门前献花悼念。
随后几天,更多的同学也陆续跟进,大家还在学校的黑板上写满了留言,字里行间满是哀思,以此共同缅怀和告慰这位科学巨擘。
📚 阅读
AI 的「左手倒右手」游戏:万亿淘金热背后的金融闭环
AI 生态正爆发出万亿价值,英伟达(NVIDIA)和 OpenAI 的估值高不可攀。但如果,这场盛宴的大部分资金,只是在牌桌上的玩家之间「左手倒右手」呢?
欢迎来到 AI 的 「循环融资」 游戏。
这个机制很简单:
- 英伟达投资一家 AI 创业公司。
- 这家公司转身就用这笔钱,向英伟达下达巨额 GPU 订单。
- 结果? 英伟达财报收入暴涨,它持有的股权估值也随之飙升。它在用自己的钱,创造自己的收入。
玩得最高明的还不是英伟达,而是微软和亚马逊。
他们对 OpenAI 和 Anthropic 的百亿「投资」中,有相当一部分是自家的云服务积分。这好比我「投资」你 1000 元,给的却是我自家餐厅的储值卡。你必须在我这里消费,这笔钱立刻变回我的高利润收入。
在这场游戏中,他们几乎稳赚不赔。
而处在风暴中心的是 OpenAI——它正疯狂烧钱,它必须依赖这些「投资」来支付账单,而讽刺的是,这些账单的收款方正是它的投资者(微软、英伟达)。
那么,谁会是第一个倒下的?
盯住 CoreWeave。这家公司 100% 押注 AI,却背负着 91 亿美元的「垃圾级」债务。它是煤矿里的金丝雀,是这场资本闭环最脆弱的一环。
这和 2000 年的互联网泡沫一样吗?不完全是。今天的 AI 技术是真实且强大的,而不是虚无缥缈的「点击量」。但支撑它的金融结构,却异常脆弱。
技术是真实的,可钱的流向却可能只是一个精巧的幻觉。
🔗:ALL IN: AI’s House of Cards?
🤖 AI
别了,A/B 测试:我在 AI 实战 2 年,推翻的 3 个「旧常识」
你是否还在痴迷于拆解漏斗,为 A/B 测试提升 0.2% 而沾沾自喜?
在移动互联网时代,这是我们的圣经。但在投身 AI 产品两年后,我发现:对过去成功路径的依赖,正成为我们最大的枷锁。
每天模型都在迭代,我们抓着「旧地图」探索「新大陆」,结果只是在错误的细节上精雕细琢。被现实毒打后,我只想分享 3 个「反常识」的新认知。
1. 放弃「局部最优」,拥抱「判断力」
我们曾被 A/B 测试「异化」,习惯用数据规避决策。但 AI 的 0-1 阶段充满不确定性。当一个新功能数据惨淡,我们的本能是「优化漏斗」,但真相可能是:你的产品很棒,只是还没找到那批「对」的用户。
在 AI 项目中,数据是滞后的。我们必须找回「判断力」。在这个快速变化的领域,基于深度理解的「信仰」远比短期数据更重要。
2. 别迷信「有用」,「好玩」常常赢在起跑线
我们过去的信条是「解决痛点」。但在 AI 领域,「好玩」的需求往往比「有用」更容易跑出来。
为什么?因为当下的 AI 在「提高效率」这类确定性任务上依然脆弱、充满幻觉。但如果你利用它的创意能力去满足「好玩」的需求——比如 AI 特效——用户会惊叹于它「做到了之前做不到的事」。这不仅管理了预期,更创造了全新的增量市场。
3. 停止「指挥」模型,像「带新人」一样「教」它
这两年最大的弯路,是把模型当成一个「工具」,试图让用户用一个「万能 Prompt 输入框」来指挥它。
我们忘了,普通用户根本不想「写 Prompt」。
我们最大的认知转变应该是:不要把模型当成机器,而是把它当成一个「极度聪明,但对你业务一无所知」的新员工。 你的工作不是「指挥」它,而是「帮助它 Landing」。真正的 AI-Native 产品,是设计一个能最大化发挥其「才智」的系统。
做 AI 产品,最常有的感受就是「失控」。用户与模型的互动,总会演化出我们计划之外的结果。别对抗这种失控。我们所要做的,就是准备好自己,迎接那个尚未被计划出来的未来。
AI Agent 阵亡率 95%:那 5% 的幸存者做对了什么?
我们正处在「万物皆可 Agent」的时代。然而,在旧金山一场汇集了 Uber 等巨头的技术大会上,一个残酷的共识浮出水面:在真实的生产环境中,95% 的 AI Agent 项目都失败了。
它们「死」于幻觉、泄密、成本失控,或仅仅是无人可用。
为什么我们投入了如此多的精力,却制造了如此多「死在发布时」的产品?这场闭门会议揭示了那 5% 幸存者的共同点。他们不再痴迷于模型本身,而是转向了五个更深层次的架构共识。
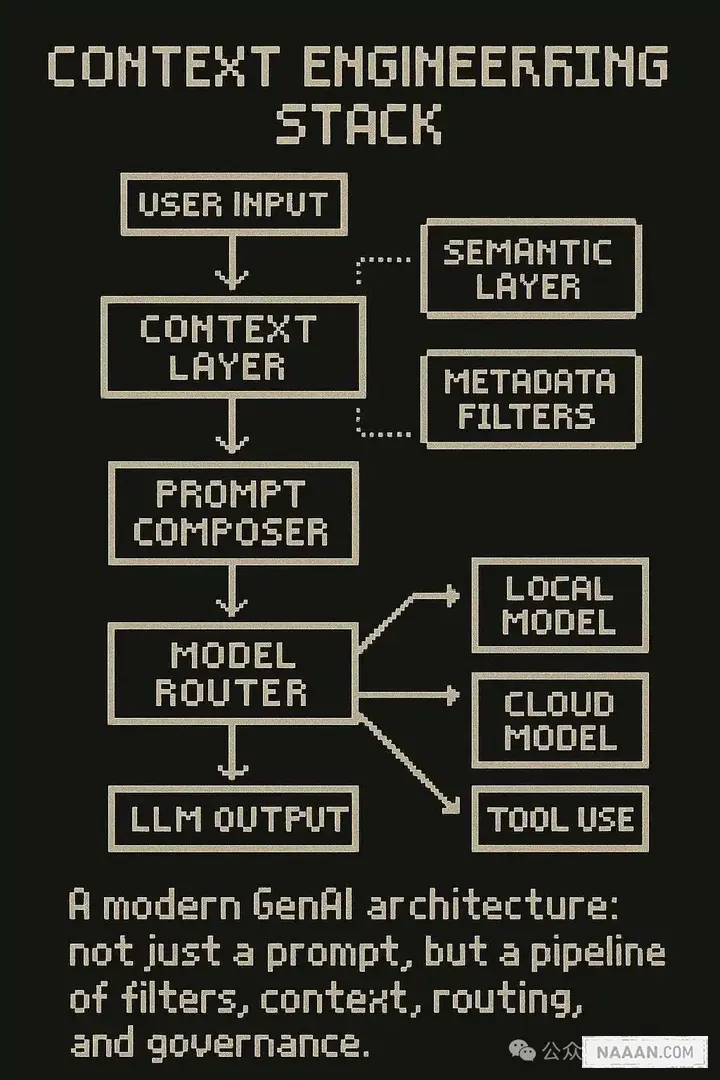
一、你不是在做 AI,是「上下文选择系统」
我们都经历过那种挫败感:上下文给多了,模型反倒「懵了」;给少了,任务又完不成。
幸存的团队已转变思路:**上下文工程(Context Engineering)就是新的特征工程。**他们不再把上下文当作一团「字符串」丢给模型,而是将其视为可测试、可审计的「构件」。他们采用双层架构:一个「语义层」负责向量搜索,一个「元数据层」则根据文档类型、时间戳或权限进行强制过滤。
二、当「Text-to-SQL」的尝试者无一幸存
会上有一个戏剧性时刻:当主持人问及「谁已将 Text-to-SQL(自然语言转 SQL)成功部署到生产环境?」
现场 600 多名顶尖工程师,没有一个人举手。
这并非没有需求,而是因为难度高到爆炸。自然语言天生模糊,而「活跃用户」这类术语,LLM 根本无从知晓其在公司内部的严格定义。这引出了信任问题——如果连数据都不可信,谁敢用?
幸存者的做法是:将「人在环路」(Human-in-the-loop)作为标配。 AI 必须是助手,而不是自主决策者。
三、记忆不是功能,它是一个隐私雷区
我们都希望 AI 能「记住」偏好,但「记忆」绝非一个简单的功能。
一位工程师分享了他的经历:他让 ChatGPT 推荐家庭电影,AI 竟直接建议:「这里有几部适合 Claire 和 Brandon(他孩子的名字)的电影。」他当下的第一反应是震惊:「你为什么会知道我孩子的名字?」
这种「有用」的个性化和「令人不安」的监视,界限极其模糊。顶级团队正因此在探索如何构建一个安全、可移植、归用户所有的记忆层。
四、别用「上帝模型」,用「模型编译器」
在生产环境中,你不会用一个重量级模型去回答所有问题,成本和延迟会压垮你。
幸存者们都在使用「多模型编排」策略,更像一个编译器:简单查询走本地小模型瞬时响应;复杂分析才调用昂贵的 Frontier 模型。这种自适应策略,是产品规模化后保持可行的关键。
五、对话不是万能的,别扔掉你的 GUI
「如果我只是想叫一辆 Uber,」一位参会者提到,「我不想对着手机说话,我只想点三下,车就来。」
这是对当前「万物皆可聊天」趋势的清醒反思。
与会者达成的共识是:对话适合消除学习曲线,而 GUI(图形界面)适合实现精确控制。 最佳实践是混合模式:用对话作为零门槛的入口,但始终提供 GUI 来进行迭代和细化。
护城河不在 Prompt,在「脚手架」
我们花了太多时间在「提示词工程」上。但这场峰会告诉我们,AI 产品的真正护城河,在于那些看不见的「脚手架」——上下文工程的深度、记忆设计的巧思、多模型编排的可靠性,以及建立在权限和控制之上的信任。
这才是那 95% 的失败者所忽略的,也是那 5% 的幸存者正在全力构建的核心壁垒。
🔗:硅谷顶级团队闭门会,让Agent活下来的共识,95%的AI Agent都死了
🛠️ 工具
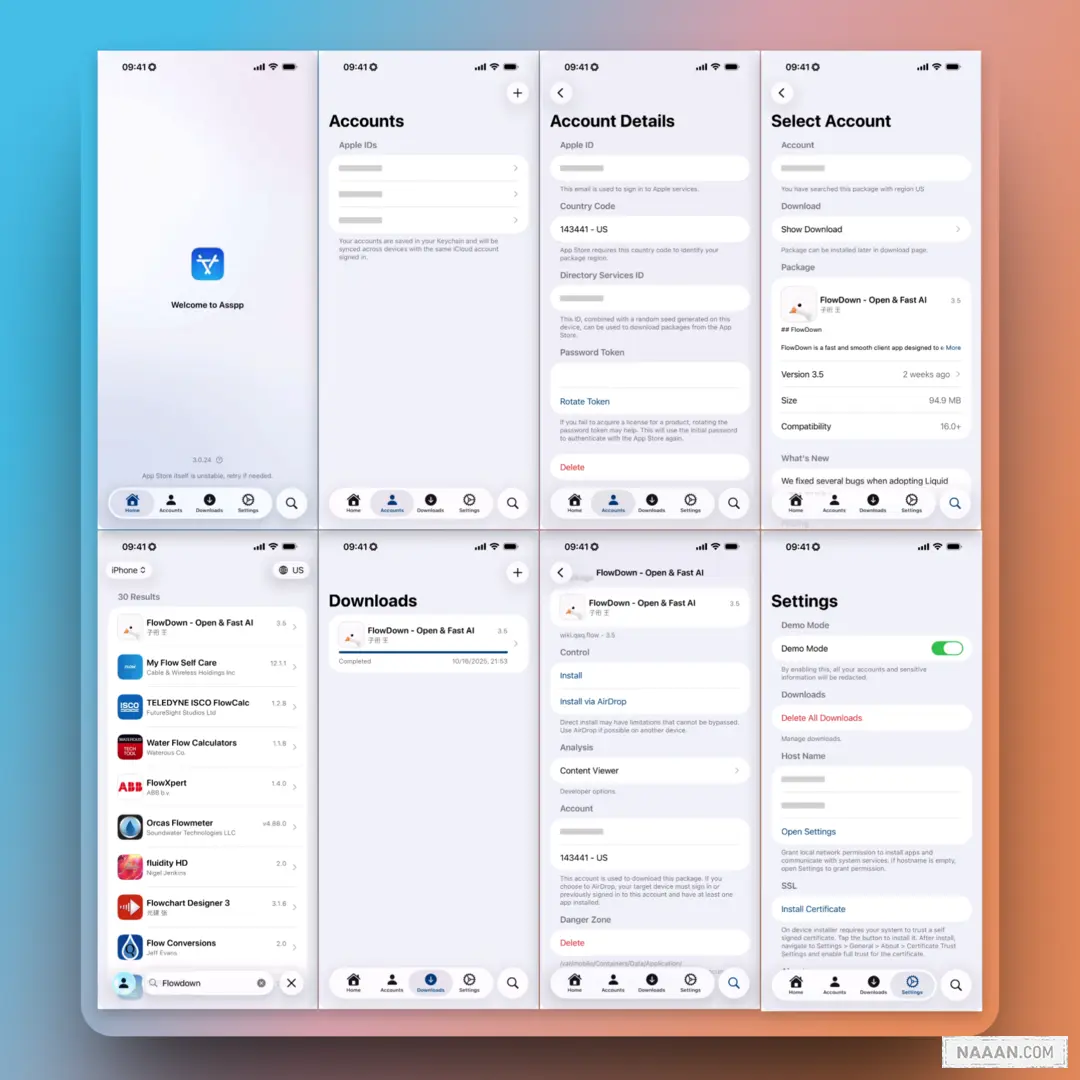
爱啪思道——在 iOS 管理多个 App Store 账户
简化多个 Apple ID 的管理和 App Store 的使用体验。它支持用户跨区访问 App Store,轻松搜索和下载应用。用户可以在非越狱设备上安装和分享 IPA 文件,还能快速将免费应用加入购买记录,以及下载应用的历史版本。这款工具特别适合需要频繁更换账户或地区的用户。
🔗:https://github.com/Lakr233/Asspp/blob/main/Resources/i18n/zh-Hans/README.md
✨ 随便看看
- 《ChatGPT 成人模式要来了,但作为成年人我一点都不高兴》 一文,深入剖析了 OpenAI 即将推出的成人模式及其潜在影响。
- 《OpenAI’s new deal with Walmart shows how AI is going to shake up the shopping experience》 一文揭示了人工智能如何重塑零售购物体验的最新动态。文章指出,美国最大零售商沃尔玛与 OpenAI 达成合作,允许消费者直接在 ChatGPT 应用内完成购物,标志着 AI 代理购物正迈向主流。