Scale AI
ChatGPT 背后的模型是 GPT-3.5-turbo,去年 OpenAI 发表了一篇《Training language models to follow instructions with human feedback》的论文,介绍了 GPT 3.0 到 GPT-3.5 模型的演进过程。
使用标注者编写的提示,然后使用监督学习来微调 GPT-3,之后再通过人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)进一步微调这个监督模型。在评估后,13 亿参数的 InstructGPT 模型的输出优于 1750 亿参数的 GPT-3。此外,InstructGPT 模型在信息真实性上有所提高,在生成有害输出方面有所减少,同时具备内容泛化的能力。[1]
在第一阶段人工主要标注了以下数据集:
- SFT 数据集: 13,000 条数据。标注人员直接根据 prompt 集中的问题,写出对应答案。
- RM 数据集: 33,000 条数据。该数据集通过将 prompt 集中的问题再次喂给经过第一阶段微调后的 GPT 模型,数据标注人员针对 GPT 的不同回答作出排序。
同时在论文中说明了这部分标注人员主要来自于外包或 Scale AI。(也有资料说是 Scale AI 和 OpenAI 各找了 30 个博士做语料标注,但是暂时没有找到消息来源。)
一、Scale 发展情况
Scale 是为 AI 训练提供数据服务的公司,Scale 目的是「建立以数据为中心的基础设施平台」以「加速人工智能应用的发展」。

2016 年,Alexandr Wang(麻省理工学院辍学)和 Lucy Guo(卡内基梅隆大学辍学和 Thiel 研究员)在 Quora 实习期间结识,后来进入 Y Combinator 春季批次。Y Combinator 当时有一个机器学习相关的创业项目,人工智能技术没有遇到大问题,但是如何获取训练用的数据一直无法解决。
因此 19 岁的 Alexandr 和 21 岁的 Lucy 成立了 Scale AI,仅仅 3 年后 Scale AI 就成为了一家独角兽公司。2021 年,Scale AI 已经成为了数据标注领域的龙头,估值 73 亿美元。
第一版本,他们的方向是:一行代码搞定繁杂的人工任务。(原来的名字叫,Scale API。)

主要能力包括,人工审核、数据提取、会议安排、数据标注、电话信息提取。Scale 认为自己是一个更可靠、更高质量的 Mechanical Turk(亚马逊的众包平台)。
Alexandr Wang,认为 Mechanical Turk 是基本众包模式,任何人都可以注册成为 Turker,这导致质量非常低。当用户对规模和质量有要求的时候, Mechanical Turk 不会有所管控。[2]
图片来源 [3]
成立 3 周后,和 4 家企业达成合作,另有 7 家正在试用,首月有 20,000 的请求量。(定价是 0.5 美元 一个请求,比 Mechanical Turk 贵 3-5 倍)
在 2017 年 7 月,Scale 发布了图像标注、OCT 翻译、分类、对比、数据收集
等 6 个 API, 同时宣布获得 450 万美元 A 轮融资。在 A 轮融资中,Scale 公布了其更大的野心,不仅是更好的 Mechanical Turk,而且要训练更好 AI 数据。同时也将 Scale API 改成 Scale AI。
我们的客户一致认为,将 AI 与人类智能准确结合,是建立可靠人工智能技术的关键。因此,我们相信 Scale 将成为 AI 下一波发展的基础设施。[4]
在 2018 年 8 月,借助数据标注在自动驾驶中起到的作用,Scale 获得了 1800 万美元的 B 轮融资:
在自动驾驶领域,即当今深度学习最突出的应用场景之一,Scale 已经成为标注数据的行业标准。我们已经与许多行业领导者合作,如通用汽车、Cruise、Lyft、Zoox 和 nuTonomy 等。我们已经标注了超 20 万英里的自动驾驶数据(大约是地球到月球的距离)。[5]
2019 年 8 月,Scale 宣布获得 1 亿美元的 C 轮融资,Scale 在这一轮融资后估值达到 10 亿美元。此时,它的客户不再只是自动驾驶公司,还有自然语言和内容理解、电子商务和搜索、制图、机器人技术、增强现实和虚拟现实、线下零售等。
该平台提供 AI 系统所需的大量高质量数据集。我们结合使用机器学习和人工标注这些数据。我们将这些高质量的实况数据传回给我们的客户,然后他们能够构建世界级的模型来解决现实世界的问题。[6]
Scale 的长期目标是提高机器自身标注的准确率,这将推动成本下降,提高利润率。在 2020 年第三季度,仅仅四年时间,Scale 就达到了 1 亿美元的 ARR 的规模,成为有史以来达到这一里程碑的最快公司之一,并且有 69% 的利润率。
20 年底,Scale 又获得了 1.55 亿美元 D 轮融资,并强调了新业务 Scale Nucleus:
我们的团队正在解决人工智能开发的下一个瓶颈问题:跨团队管理整个 AI/ML 应用的生命周期。从零构建、部署可扩展的机器学习基础设施是低效且昂贵的,我们在 8 月推出了 Nucleus,以实现整个 AI 开发周期的无缝协作。[7]
21 年 4 月,Scale 获得了 3.25 亿美元的 E 轮融资,并发布了「在每个行业部署 AI」的融资公告。此时该公司的估值为 73 亿美元, ARR 接近 3 亿美金。Scale 的战略定位进一步发生变化,成为一家基础设施公司 (infra)。
Scale 正在打造一个基础设施,使企业能够管理整个人工智能项目的生命周期。无论他们是拥有一个内部的 AI 团队,还是需要一个 MaaS( 即 Models-as-a-Service,模型即服务)的解决方案,我们会与客户合作,从零开始建立他们的战略,并提供基础设施,以建立高性能模型。」
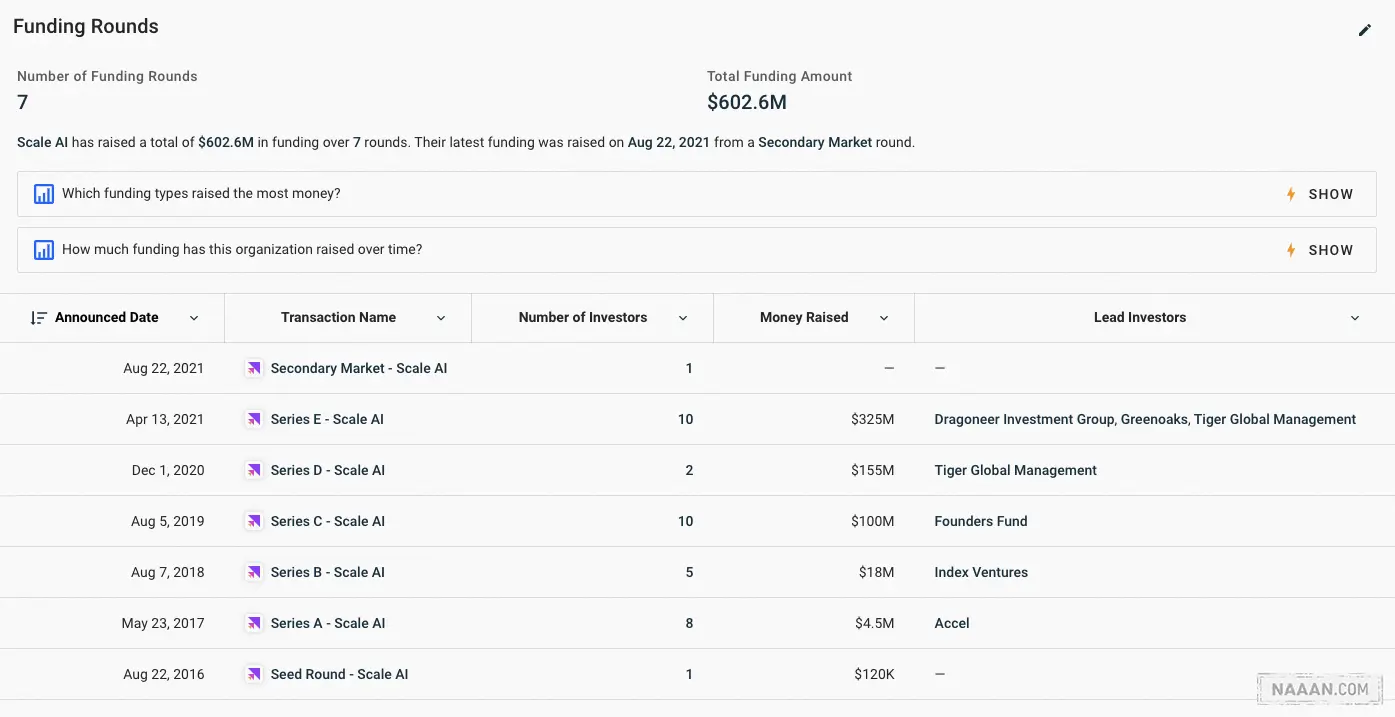
融资情况来源 - crunchbase [8]
但是由于市场的不确定性,23 年 1 月,Alexandr 在官网中说 Scale 将裁掉 20% 的全职员工。[9]
二、Scale 的产品线
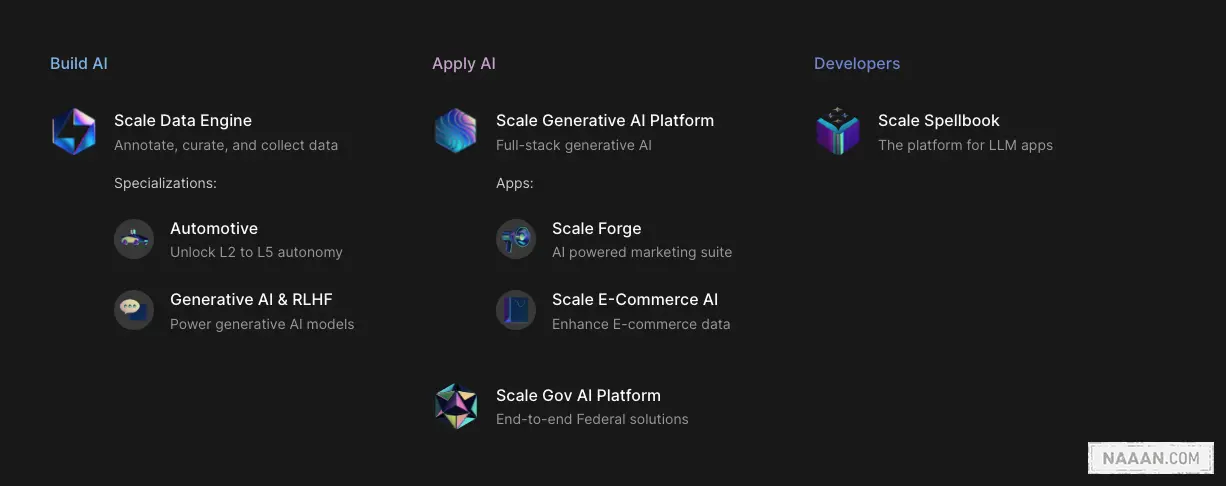
目前,从官网上看,Scale 主要分为 3 大块
- Build AI(Data Engine)
- Apply AI(Generative AI Platform)
- Developer(Spellbook)
1. Build AI(Data Engine)

20 年 Scale 发布 Nucleus 后,产品主要围绕着机器学习模型生命周期的构建。Scale 通过提供各种产品解决方案(包括数据标注、数据管理、自动数据提取、模型评估和合成数据生成)来管理 ML 生命周期的每一步。
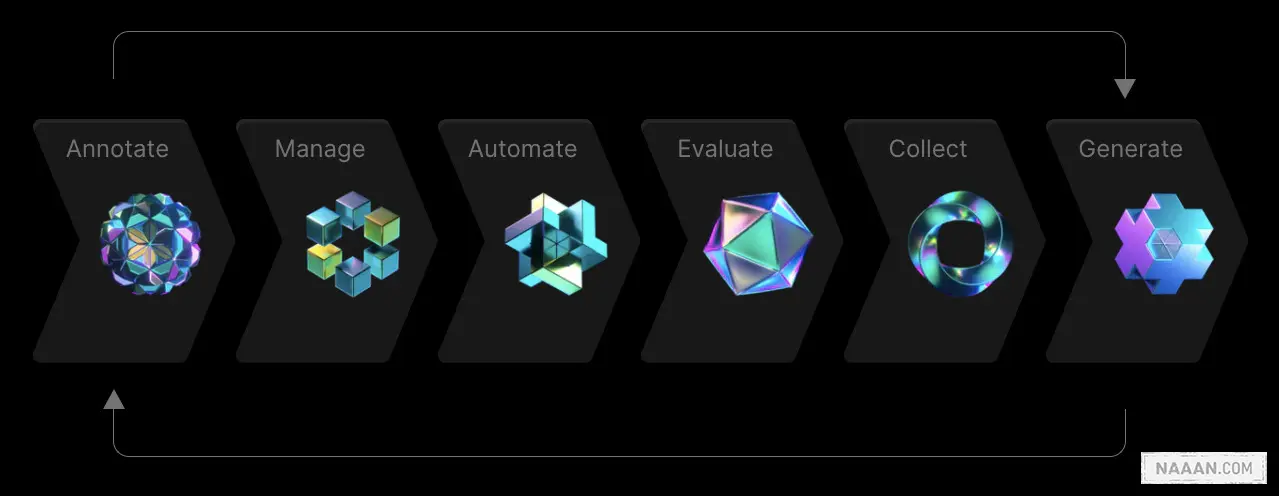
标注: 这是 Scale 的核心业务,其重点是在保持标注质量的前提下,增加由算法而非人工的标注量。
管理: 让企业通过一个可视化的云端界面来管理、策划和理解他们的数据。该产品为 Scale 拓展了更多小企业客户。
自动化: 自主构建的机器学习模型来处理和提取文件中的数据。它可以为客户提供训练有素的 ML 模型,在某些情况下甚至可以完全取代对 AI/ML 团队的需求。
评估: 客户可以通过 API 上传预测结果、跟踪模型在一段时间内的表现、比较运行情况、根据指标对失败案例进行分类、并在精选数据上建立模型单元测试。
收集: Scale 提供帮助公司收集数据的潜在产品,能够收集来自 70 多个国家的 50 多种语言的文本和音频数据。
生成: 生成人造数据,为模型提供更多可用数据。很多业务使用它验证边缘案例。或增加标注语料。
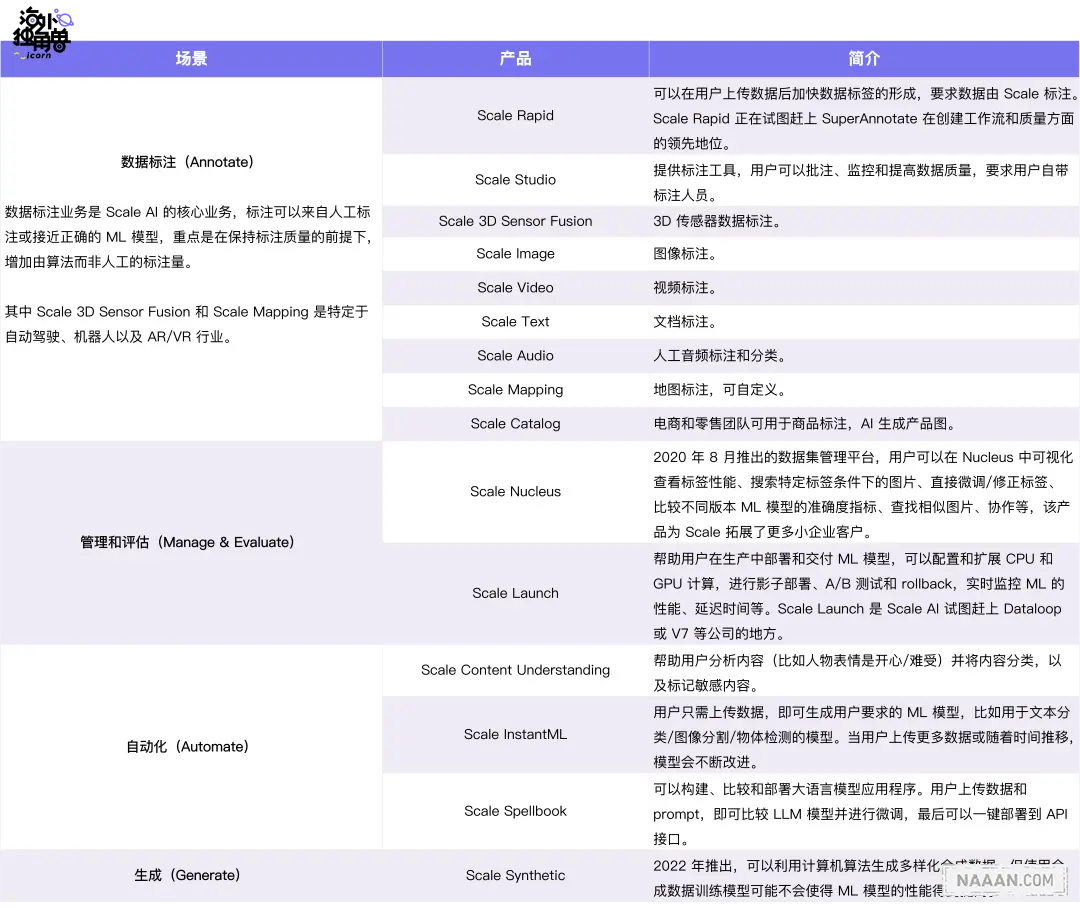
Scale 的产品
1.1 数据流程
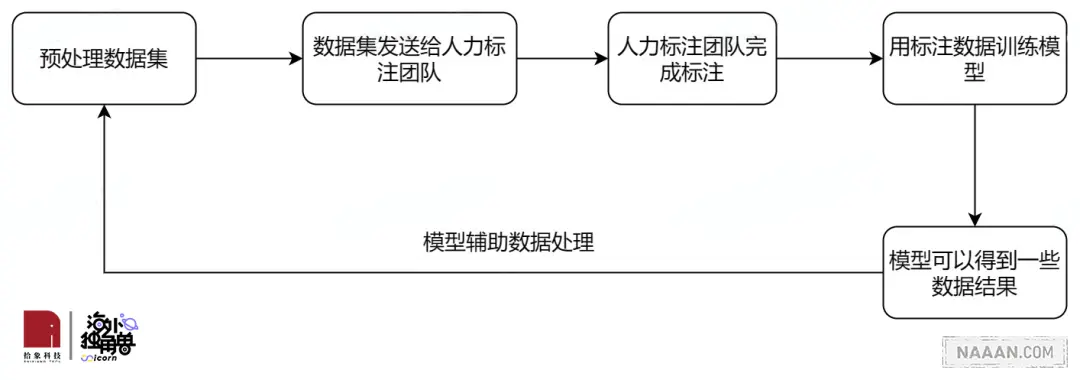
当 AI 公司负责人需要对数据集标注时,他会编写有关如何标注数据的说明。这些说明可以用于各种任务,例如标注图像中的内容、注释音频剪辑或确定内容评论是正面还是负面。然后,负责人会上传 10 到 50 个数据示例,以确保人工或机器正确遵循说明。
Scale AI 会在一到三个小时内返回这些结果,并由负责人确认是否质量阈值。如果没有,开发人员可以再提交 10-50 个样本。一旦开发人员确认正确遵循了说明,他们就可以规模化的上传张图像。[10]
同时,负责人可以定期来抽查并评论质量情况,予以调整训练结果。
Scale AI 会配备有「专家标注员」,帮助避免在一些标注流程中发现的问题。比如一个标注任务可能被发送给五个人,多数结果被视为有效标注。问题是大多数人可能是错的。例如,如果任务要求某人区分乌鸦和黑鸦,但五分之四的标注员可能会将黑鸦误认为是乌鸦。这时,Scale AI 引入了「专家标注员」,然后他会尝试优化 ML 自动化标注过程。
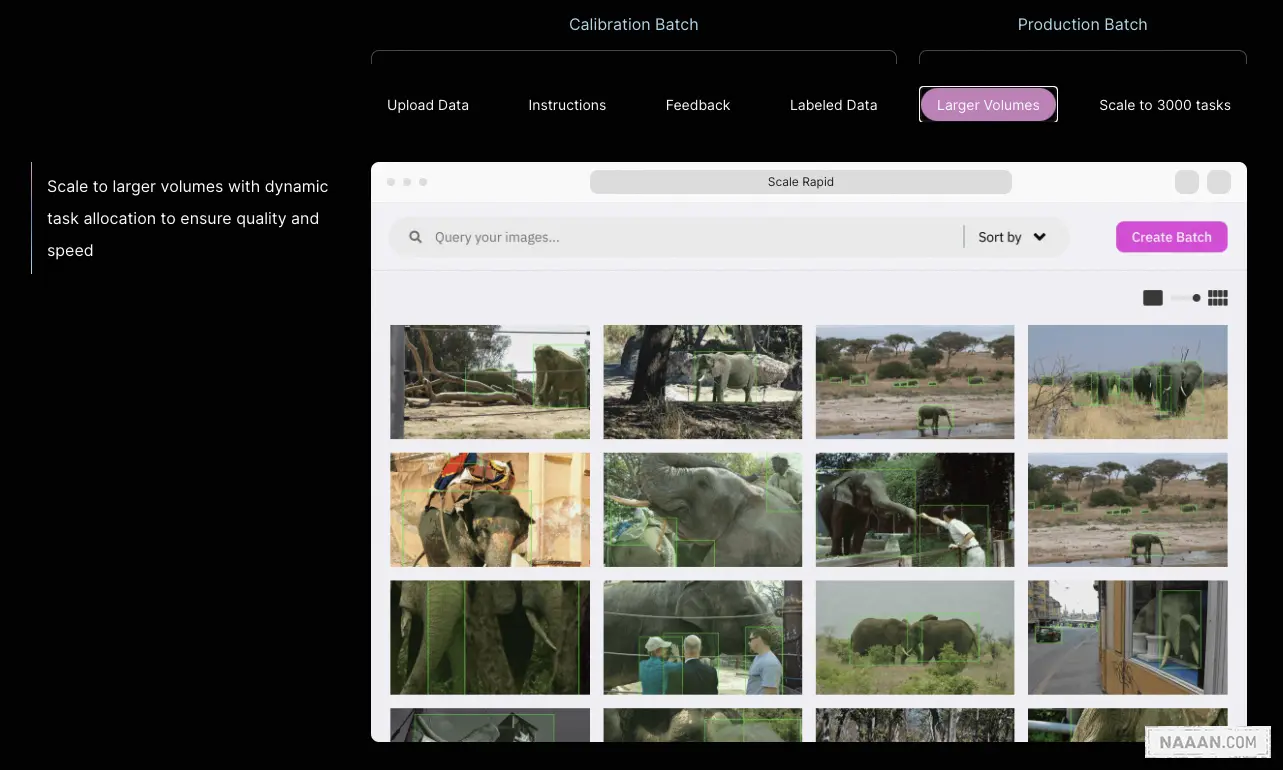
在这个过程中,Scale 将会努力减少数据标注过程中的人工参与比例,通过提高数据标注能力的模型,来降低标注成本。
Scale 同时也受益于数据网络效应,随着更多的客户使用 Scale,Scale 将需要更多的标注人员或者更好的算法,标注人员更快地给更多客户的数据贴上标签,Scale 的模型也将进一步改善,客户将会更加愿意使用 Scale,使整项业务旋转得更快。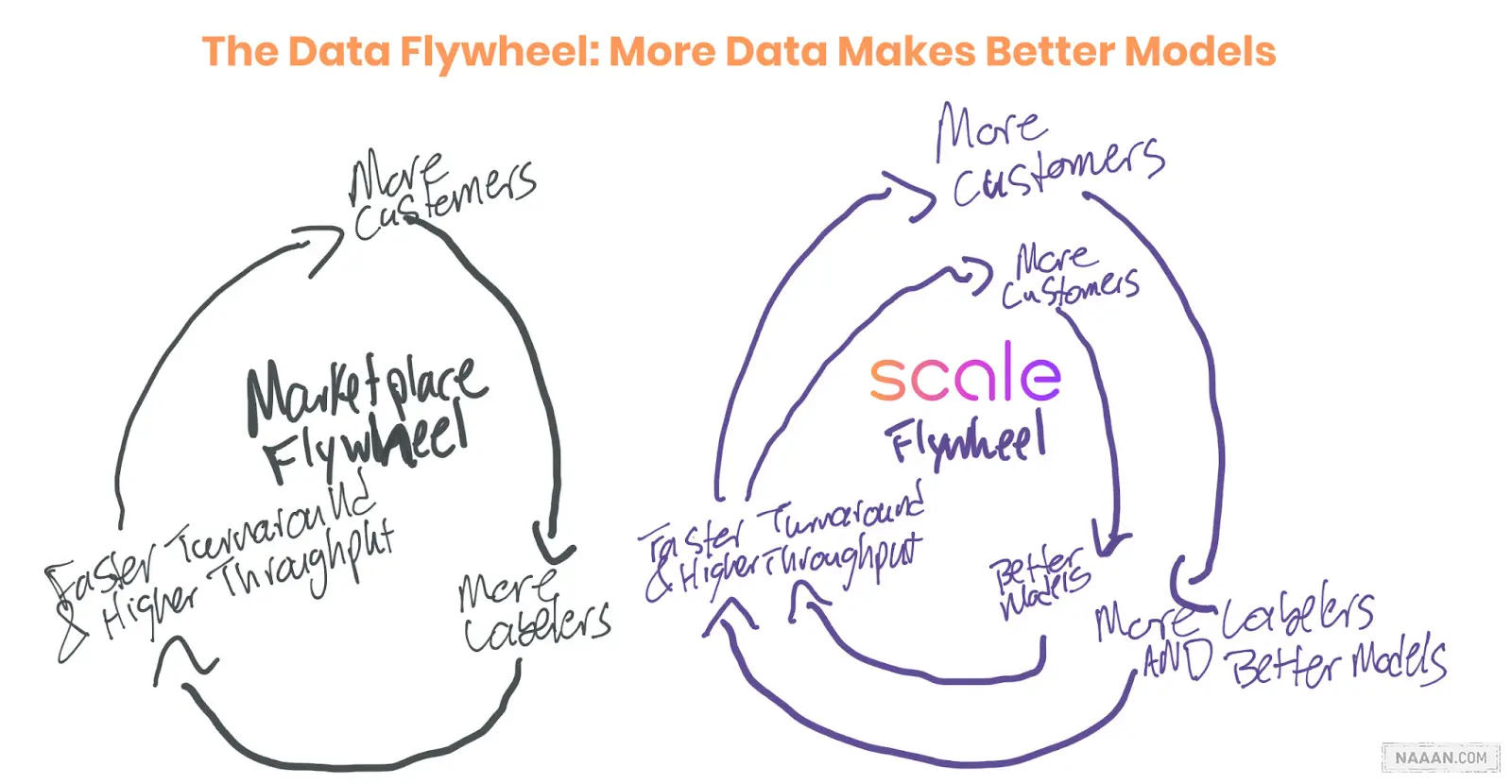
更多的客户 → 更多的标签人员/更好的模型 → 更快的周转率和更高的吞吐量 → 更多的客户
2. Apply AI(Generative AI Platform)
**Scale Catalog** 主要针对电商和零售企业,除了提供标注服务,还能自动生成产品图,是 Scale 切入 Generative AI 应用领域的一款核心产品3. Developer(Spellbook)
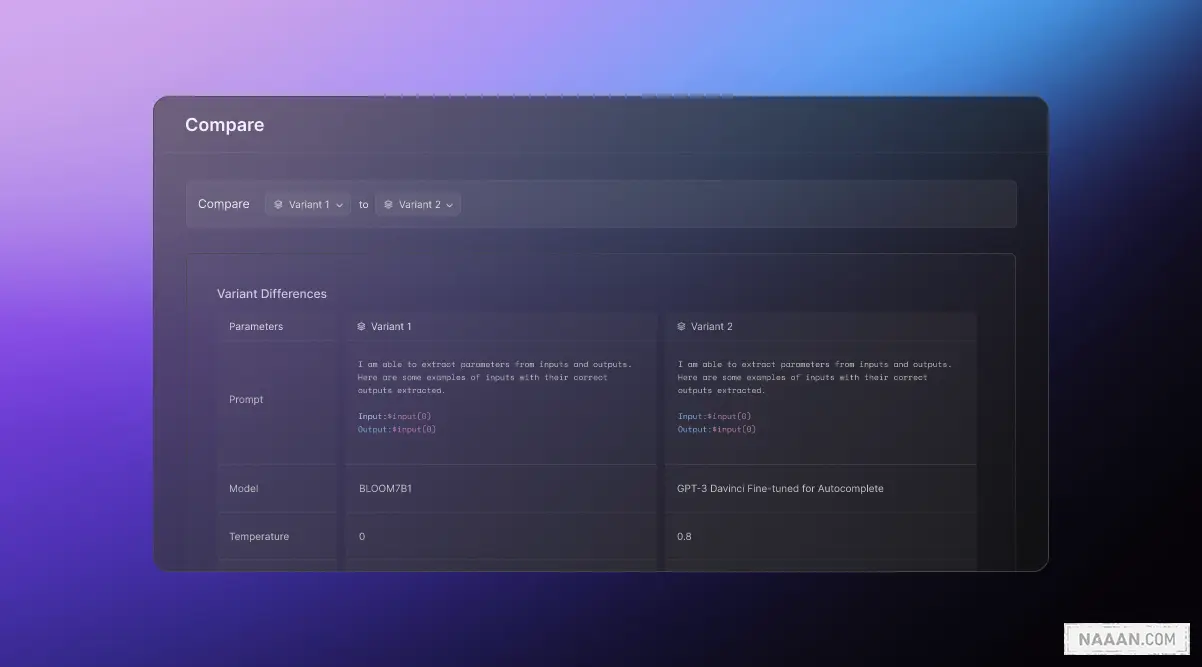
Scale Spellbook 做一个基于大语言模型的 to 开发者的工具平台。
上传
上传数据并轻松查看和编辑您的 prompt。
对比
快速比较不同 LLMs, prompts, and fine tuning 策略的实验。
微调
对现有数据进行 fine tune,以不断提高模型性能。
部署
一键部署,即可通过内置监控和分析。
4. 发布时间线
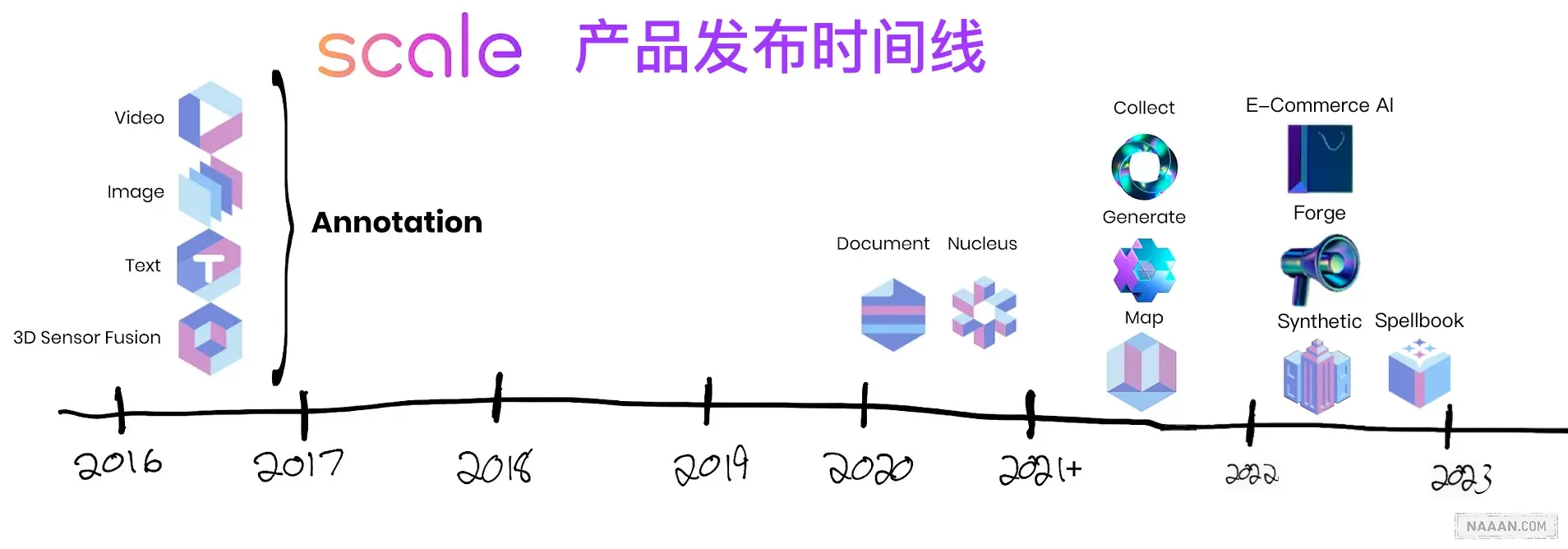
可以看到 22 年之前,Scale 主要聚焦在 标注 领域,2022 年之后开始发力 基础设施公司。
从 Scale 的产品拓展情况来看,Scale 正非常激进地切入 MLOps 和 LLM 领域,提供各类工具、平台和服务。不过这只是 Scale 寻找第二增长曲线的一些尝试,产品销售情况并不理想,最后能有稳定需求、贡献主要收入的还是数据标注。
三、业务情况
1. 客户
目前,Scale 的客户已经包含国防部和美国空军;金融科技公司,如 Brex、PayPal 和 Square;运输和物流先驱,如 Flexport、通用汽车、Luminar 和 Oshkosh;消费者品牌和产品,如 Etsy 和 Pinterest;一些世界上最大的技术领导者,如三星和 SAP;管理葡萄酒收藏的 CellarEye;用于优化原木库存和管理的 TimberEye,以及用于加快房地产交易的 States Title。

在俄乌战争中,标注顿涅茨克的马里乌波尔被摧毁的区域。[11]
2. 职员情况
2021 年 3 月, Amazon Robotics VP Brad Porter 加入了 Scale AI 担任 CTO。
2021 年 5 月, Scale AI 聘请前美国首席技术官 Michael Kratsios 担任战略主管。
2022 年 2 月,Scale AI 有 450 名正式员工。[12]
2022 年成立 200+ 人的团队,专门服务于美国政府的数据标注服务。(暂时没有查到自有标注团队总人数)
同时,有非公开资料表示 Remotasks 是 Scale 的子公司,有 24 万标注人员分布在肯尼亚、菲律宾和委内瑞拉等国家/地区工作。为了避免竞争对手的打击,Scale 有意将两个品牌分开。[13]

同为给 OpenAI 标注的公司 Sama(原 Samasource)支付给工人的税后时薪仅为 1.4 美元 [14]。
四、竞争

Scale 的竞争对手包括:公司内部自建的数据标注团队;谷歌、微软和亚马逊等科技大厂的数据标注服务;数据标注创业公司。

1. 公司内部自建的数据标注团队
由于某些数据比较敏感,有的公司会选择内部自建数据标注团队,作为 Scale 等外包方案的补充。例如 Airbnb 使用内部数据标注产品来标记隐私数据,并用于公司内部的机器学习模型,但是对于不敏感的数据,Airbnb 通常会外包给第三方供应商进行标注。
• 第三方供应商做数据标注可以比 Airbnb 内部自建团队更便宜;
• 第三方供应商具有灵活性,可以根据 Airbnb 的需求灵活调整;
• 数据标注并不是 Airbnb 的重点业务,第三方供应商的工具可以更准确高效地完成标注。
2. 数据标注创业公司
在 AI 数据标注方向的主要竞品也陆续出现,OpenAI 以及即将推出的 AI 重量级 Cohere 同时使用 Scale 和 Surge。Labelbox 和 Snorkel AI 专注于将 AI 引入非科技企业,也获得了数十亿的估值。
Labelbox
Labelbox 成立于 2018 年,是一个数据训练平台,为机器学习应用创建和管理标注数据。Labelbox 2021 年 80% 的业务来自企业,Labelbox 的软件平台面向旨在促进训练数据迭代循环以提高 ML 性能的企业。LabelBox 提供专有的 ML 支持的预标注,而不是主题专家编写自己的标注函数。LabelBox 还提供强大的工具来管理广泛分布的注释团队,包括新产品 Boost,提供外包标签专业知识。LabelBox 的创始人还声称他们不与 Scale AI 或 Snorkel AI 竞争,而是主要取代亚马逊的 SageMaker 和内部工具。它于 2022 年 1 月以 10 亿美元的估值筹集了 1.1 亿美元的 D 轮融资。它在零售、制造、娱乐、保险和医疗保健领域开展业务。其客户群包括 P&G、Burberry、Dialpad 和 Ancestry。
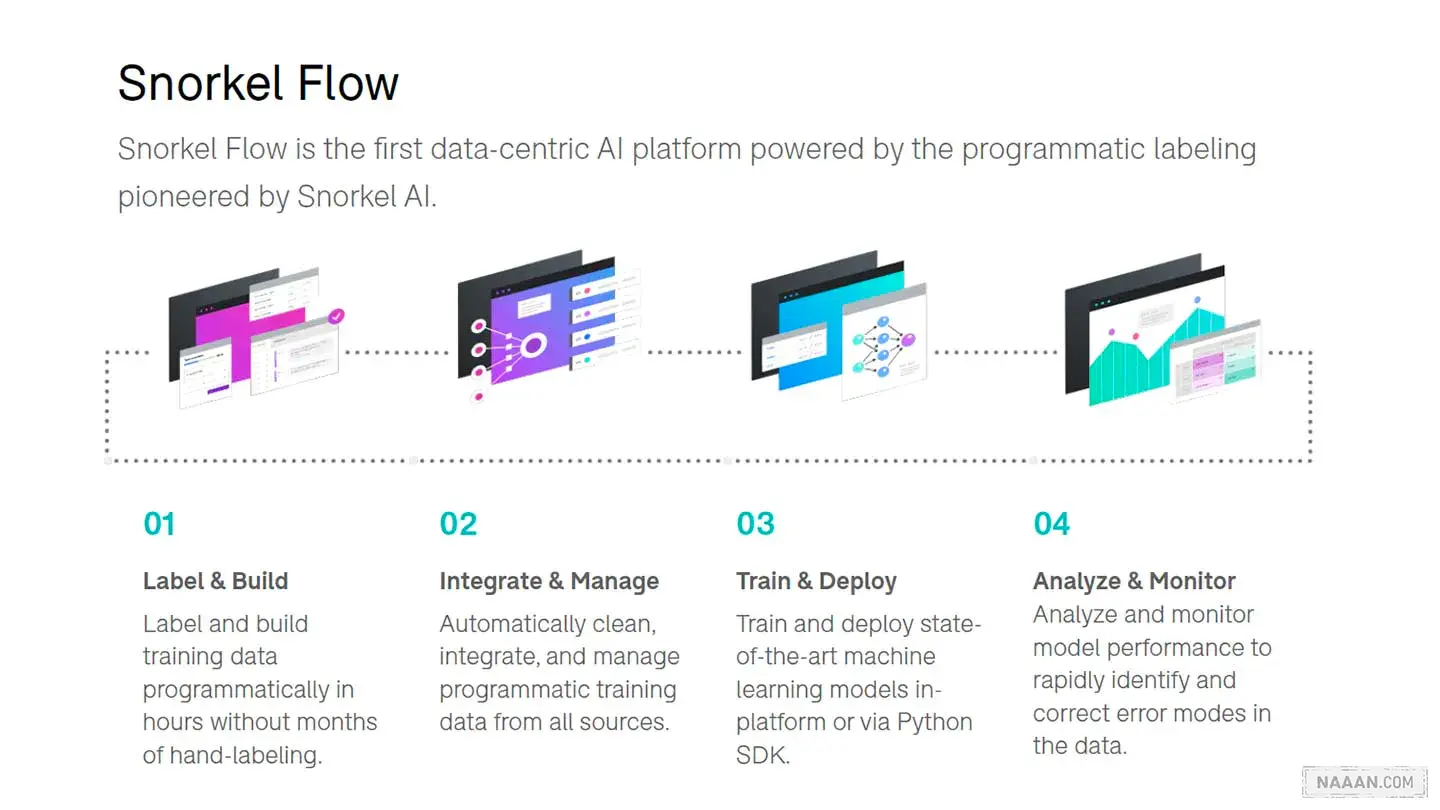
Snorkel AI
由斯坦福大学开发,Snorkel AI 是一家自动化数据标注平台公司,于 2019 年成立,其主要产品是在不需要人工注释的情况下完成标注的自动注释工具。其客户主要包括 IBM、Express-Scripts 等大型公司。相比 Scale,Snorkel 的优势在于更专注于文本和 NLP,以及成本较低,所以用户如果只是处理文本数据,一般会选择 Snorkel 而不是 Scale。Snorkel 的劣势在于视频、图像、地图等处理能力非常有限。
Surge
Surge 是另一个成立于 2020 年的数据标签平台。它已经筹集了 2500 万美元的资金。它用于财务分类、内容审核、客户支持等。它的客户包括推特、亚马逊、纽约大学和 Twitch。
差异点:
1. Labelbox和Scale AI主要提供标注工具和标注数据管理解决方案,适用于需要大量高质量标注数据的企业。与此相比,Snorkel AI和Surge AI主要提供数据增强和半自动的标注方案。 |
五、想法
1. Scale 踩中了什么
在 Scale 之前,数据标注被外包给亚马逊的 Mechanical Turk 等众包平台,该平台笨重且缺乏质量控制,只有 Meta 和 Google 等公司才有可能合理使用。
Scale 的起步是使用 API 简化数据标注工作流程以获取大量原始数据,使用软件对原始数据进行预标注,并由人工承包商进行最终编辑和质量检查。同时他们作为数据标注行业的早期参与者,市场竞争并不激烈,有不少试错的空间。
在行业的选择上,他们最早提供的数据就是用于训练自动驾驶,因此早早就和 Waymo 等自动驾驶龙头达成合作。同时这段期间自动驾驶汽车初创公司的迅速崛起,这些初创公司需要通用供应商无法提供的大量高质量标注数据。Scale 专注于这个狭窄的用例,比其竞争对手更擅长标注 LiDAR 点云等复杂数据,解决了自动驾驶汽车公司的一个基本问题。[15]
从长远来看,以人为本的方法并不是正确的方法,但这对数据飞轮至关重要。当 Scale 的人类团队标注数据时,他们也在训练 Scale 的标注模型。随着时间的推移,人机比下降了;算法正在做更多的工作。Scale 已经用比世界上几乎任何人都多的人类标注训练了它的模型。对于像 Appen 这样的竞争对手来说,情况更糟,它们更像是 Upwork-for-labelers 而不是 AI 公司。」[16]
随后,Scale AI 很自然的将模型横向支持各种场景的数据标注服务。从客户和订单来看,美国的 enterprise 客户大多只认可 Scale 作为他们的第三方数据标注服务商,Scale 的客户可以说是美国 AI 各细分赛道的皇冠上的明珠,拥有最好的客户 base。
21 年开始寻求 AI 基础设施公司 的故事,发展业务增长的第二曲线。
2. 为什么中国出不了 Scale AI
1. 美国人力成本高,必须通过技术平台的方式解决跨国数据生产的问题。
从业内的判断来看,Scale 早期也走的是人工标注的路线,很可能他们的用的还是印度的的标注团队,靠着比美国更便宜、更高效的标注服务打开的市场。[17]
数据标注业务本身的门槛非常低,数据是客户提供的,「数据标注师」也没有什么硬性的技能要求,要标注图片中的「猫」,你只要认识猫是什么样就能干。
与之相对的是,随着人工智能技术的发展,标注的要求越来越高,以前画个正方形把猫框住就行,后来为了精确,要像 PS 抠图一样,这对人工的要求就越来越高。
这倒逼相关行业内企业必须先从技术的角度解决整体数据流程生产的各个存在的问题。而国内在这个行业发展的过程中再次体现出了人口红利带来的便利。
2. 国内的人工智能企业不愿意开放数据
AI 技术厂商可以向上下游延伸,相比国内数据标注公司一定是有技术优势的,企业不愿意开放自身数据,数据标注公司无法提供类似「Scale AI」针对终端传统客户需求场景的整体解决方案。
Scale AI 数据训练后的 AI 可以用来帮别的企业做数据标注,随着训练数据越来越多,Scale AI 做标注的效率也会越来越快,需要人工参与也会越来越少,数据的飞轮越来越快。
3. 思考
数据标注工作一般认为是劳动密集型产业,对于这个产业的理解就是「有多少 AI,背后就有多少人工」。Scale 将用户训练出来的结果,反过来迭代自己的 AI 模型,从而更好的实现自动化数据标注。现在看来是很理所当然当然的事情,但是国内的数据标注厂却很少这么做的。
Alexandr 对于数据准确性的理解确实很超前,他的观点是数据质量不好,就像是在屎里面训练模型。(原文忘了怎么说了)我之前对于大数据质量理解没有这么深刻。17、18 年无监督学习很火热(数据不需要预训练),比如 Facebook 的新计算机视觉系统 DINO 可以在没有任何训练数据的情况下分割图像。当问到 Wang,「像 DINO 这种无需数据的无监督学习模型对 Scale 是否构成的威胁」时,他这样回答:
无监督模型并没有消除对人工标注数据的需求,而是转移了这种需求。无监督模型将产生一个具有部分「基础」能力的模型,但要创建一个在现实世界中有用的算法,你需要已经标注过的数据来实现一个名为「微调」的过程。即使是无监督学习的顶级研究人员也在积极研究如何使用标注数据集来使该模型表现得更好。
只要模型在现实世界中应用,无论什么模型都少不了 fine tune 的过程,这个过程少不了高精准的数据。OpenAI 的 InstructGPT 的论文中也说明了高质量的数据,比低质量的数据将减少计算资源,且效果更好。
Scale 做的 Maas( Models-as-a-Service,模型即服务)让我眼前一亮,从没有想过可以跑出这种模式。由于 Scale 是可以用用户的结果去迭代自己的模型的,最终 Scale 的模型很大概率比用户的模型更接近最优。
同时,Maas 为 Scale 建立起了护城河:
- 规模经济:Scale 的客户越多,它的模型就越好,而以相同质量标注数据的成本就越低。
- 高转换成本:仅就 Scale 的注释产品而言,转换成本是相当低的,然而它通过提供更高质量的产品来留住客户。随着模型产品的推出,客户离开 Scale 成本将越来越高,因为 Scale 会随着使用情况不断改进客户的模型。如果他们更换供应商,就需要重新培训模型。
参考
- 1.Training language models to follow instructions with human feedback, arXiv, Mar. 04, 2022 ↩
- 2.Scale lets companies outsource their human-powered tasks with one line of code | TechCrunch ↩
- 3.Scale landing page design inspiration - Lapa Ninja ↩
- 4.Announcing Our Series A With Accel | Blog | Scale AI ↩
- 5.Announcing Our Series B with Index Ventures and Accel | Blog | Scale AI ↩
- 6.Scale AI’s Series C: Building the data platform to accelerate machine learning | Blog | Scale AI ↩
- 7.Scale AI’s Series D: Expanding our Team to Empower AI Dreamers | Blog | Scale AI ↩
- 8.Scale AI - Funding, Financials, Valuation & Investors, crunchbase ↩
- 9.Company Update | Blog | Scale AI ↩
- 10.Scale AI launches rapid data-labeling service | VentureBeat ↩
- 11.Scale AI Open Datasets | Mariupol Damage Identification ↩
- 12.Scale AI cuts 20% of its workforce | TechCrunch ↩
- 13.How Alexandr Wang Turned An Army Of Clickworkers Into A $7.3 Billion AI Unicorn (forbes.com) ↩
- 14.OpenAI千亿市值背后:外包数据标注员月薪不到两千,每天标注20万个单词 ↩
- 15.Scale AI revenue, valuation & growth rate | Sacra ↩
- 16.https://www.notboring.co/p/Scale-rational-in-the-fullness-of ↩
- 17.不要都在大模型赛道厮杀,ChatGPT创业还有一条潜力黄金赛道 ↩