数据指标构建方案
数据指标作为业务和数据的结合,也是数据统计的基础,也是量化业务效果的依据。数据指标是数据仓库的根基,也是数据报表呈现的依赖。

1、数据建模
数据仓库一般采用的建设方法是应用驱动,业务逻辑知识散落在各个 ETL 开发与 PD 的头脑中,缺乏整体上对源系统的一个全面了解。全面的数据调研工作对后续数据仓库模型中的设计具有非常重大的指导作用,在数据的取舍、数据整合策略、指标计算方法等方面都非常重要。
1.1 第三范式建模
范式建模法其实是在构建数据模型常用的一个方法,该方法的主要由 Inmon 所提倡,主要解决关系型数据库得数据存储,利用的一种技术层面上的方法。目前,我们在关系型数据库中的建模方法,大部分采用的是三范式建模法。
一个符合第三范式的关系必须具有以下三个条件:
- 每个属性值唯一,不具有多义性;
- 每个非主属性必须完全依赖于整个主键,而非主键的一部分;
- 每个非主属性不能依赖于其他关系中的属性,因为这样的话,这种属性应该归到其他关系中去。
1.2 维度建模
维度模型是数据仓库领域另一位大师 Ralph Kimball 所倡导,他的《数据仓库工具箱》是数据仓库工程领域最流行的数仓建模经典。维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
典型的代表是我们比较熟知的星形模型(Star-schema),以及在一些特殊场景下适用的雪花模型(Snow-schema)。维度建模中比较重要的概念就是 事实表(Fact table) 和 维度表(Dimension table)。其最简单的描述就是,按照事实表、维度表来构建数据仓库、数据集市。
2、指标模型
目前,阿里巴巴数据公共层建设的指导方法是一套统一化的集团数据整合及管理的方法体系(OneData),其包括一致性的指标定义体系、模型设计方法体系以及配套工具。
OneData 体系分为:数据规范定义体系、数据模型规范设计、ETL 规范研发以及支撑整个体系从方法到实施的工具体系。

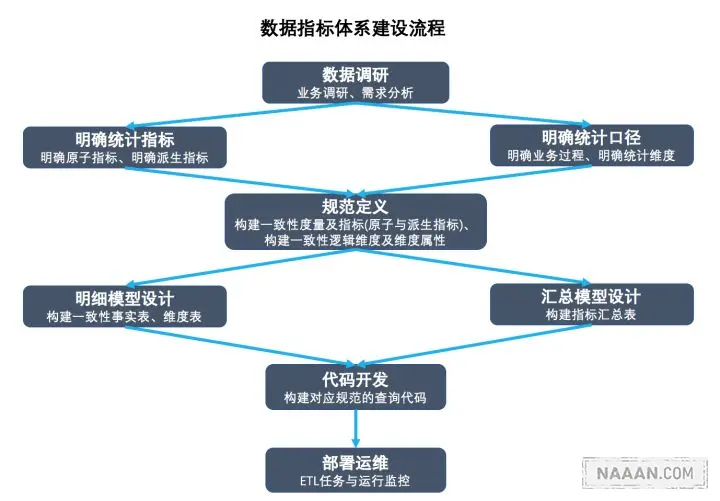
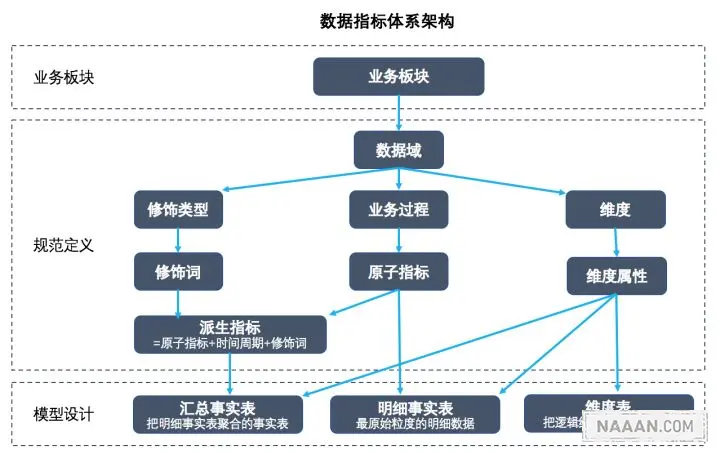
2.1 数据指标搭建流程
2.2 指标的规范定义
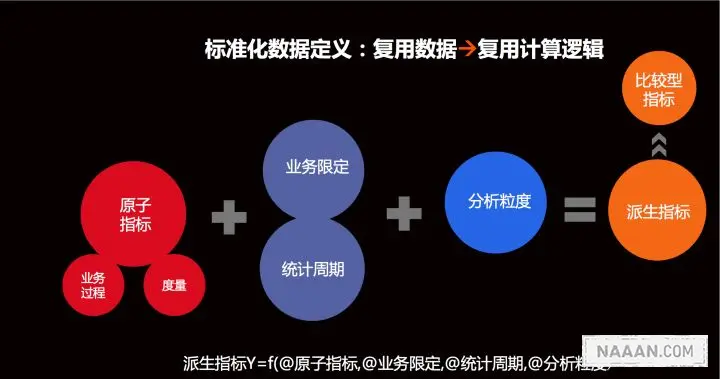
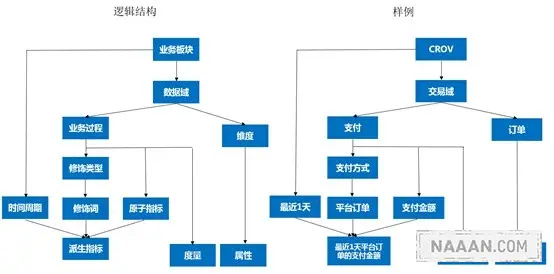
指标的规范定义,以维度建模作为理论基础,构建总线矩阵,划分和定义数据域、业务过程、维度、度量/原子指标、修饰类型、修饰词、时间周期、派生指标等。
- 事务型指标:是指对业务活动进行衡量的指标。例如,新增注册会员数、订单支付金额,这类指标需要维护原子指标以及修饰词,在此基础上创建派生指标。
- 存量型指标:是指对实体对象(如商品、会员)某些状态的统计,例如商品总数、注册会员总数,这类指标需要维护原子指标以及修饰词,在此基础上创建派生指标,对应的时间周期一般为「历史截止当前某个时间」。
- 复合型指标:是在事务性指标和存量型指标的基础上复合成的。例如,浏览 UV- 下单买家数转化率。