音乐指纹 - 算法的框架
如何让电脑听歌辩曲呢?这里用到了 music fingerprint 的算法。所谓 fingerprint 就是找到一个能代表曲子的东西,就像指纹能代表一个人一样。
Shazam
Shazam-android | Shazam-iOS Shazam 这个服务虽然是闭源的,但是有 论文
指纹生成
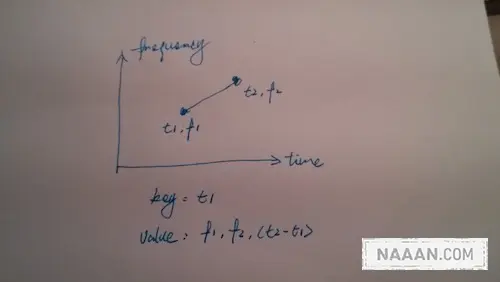
从声谱图 (spectrogram) 生成星座图 (constellation),所谓星座图就是在时间轴上取一些点(密度大概 1 秒 10 个),然后取在这些时间点上的最高能量的频率的能量 (定一个时间点,一定会有很多频率有声音,选声音最大的那个频率),星座图中的点代表该时间该频率的能量 从时间维度扫这个星座图,将点与后面 target area 里面的一堆点配对 (具体 target area 怎么定论文没说),每一对成为一个元素放入 hash 表,key 是该时间和开始时间的距离,value 就是两个点的频率和时间差 (图)
匹配和选择
手机捕捉的声音片段也用同样的方法做指纹,将这些元素和服务器中的数据作比较 (比较 hash 的 value),相同的按歌曲名字放在不同的桶里面,这个时候桶中的所谓 match 其实不一定是真的 match,有可能是匹配到了错误的位置,解决的方案就是在一个以服务器样本时间和手机样本时间为坐标的坐标系中找斜线。如果手机捕获的片段确实是服务器中歌曲的一部分,那么这条线会很明显,否则就非常稀疏或者干脆找不到。找到最符合这个标准的桶,我们就有了匹配到的歌曲。以下分别是
匹配和不匹配的样子
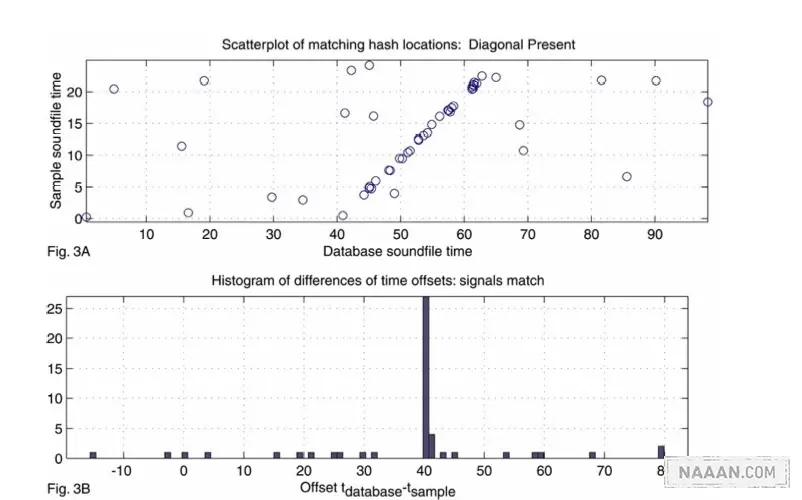
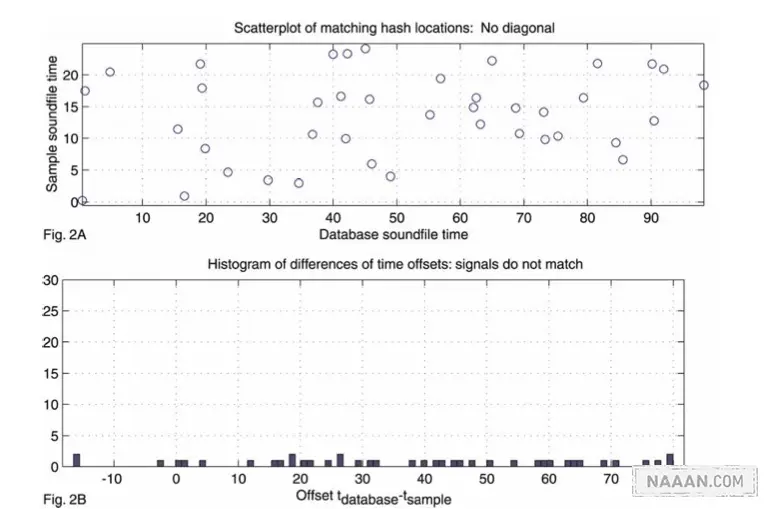
以上就是 Shazam 的指纹算法了
Echoprint
echoprint-code 这个没有现成的服务,有一些 sample 比如 ios-sample,echoprint.me 是他们的博客 echoprint 的算法和上面的就差很多了,感觉也更复杂一些,这里有 论文
指纹生成
从声谱图找到八个频段的高能点,这里和星座图不一样 (就叫带状图好了),对于每个频段纪录能量大的点,但是只有时间,没有频率,也就是说输出的矩阵一维是时间,另一维就是 8 个频段的标号。每个元素代表该时间,该频段所有频率的最高能量 指纹算法希望能通过用阈值 (每个频段独立) 过滤带状图得到一系列的能量较高的点,而且这些点和前后点的相邻距离又不会太近或者太远。这里引入 IOI 的概念 (inter-onset-interval),所谓 IOI 就是某个频段里面相邻的两个点的时间差。函数 adaptiveOnset 基本干的就是这个事情。控制 IOI 长度的方法有两个,一个是
变化阈值,另一个是硬性规定长度。控制阈值: 如果上次能量超过了阈值,阈值更新为该能量 x1.05。如果没有超过,阈值 x= e^(-1/t) t 是个变量,如果超过一定时间还没有超过阈值的能量,t 就减少 (阈值随之减少),否则 t 增加 (阈值随之增加)。所以基本上就是如果 IOI 变短,那算法就增加阈值。如果 IOI 变长,算法就减少阈值。硬性规定最小长度: 如果本次命中和上次命中太近,就把上次命中覆盖掉。除了上面的逻辑,算法还会避免一些过高的能量,在上次没超阈值的情况下本次超过阈值会改变阈值,但是不会直接纪录该点,如果下一个点小于阈值,会纪录下来 (代码中contact和lcontact干的是这个事情)。最后成为一个矩阵。下面就可以将 IOI 配对组成 hash 了,这个工作是在函数 Compute 中完成的,每个频段的每个点找到接下来的 4 个点,生成时间差 (IOI),前后相邻的 IOI 组成配对,生成 6 个对 (看图),把这些对顺序放进一个数据结构中,成为指纹。
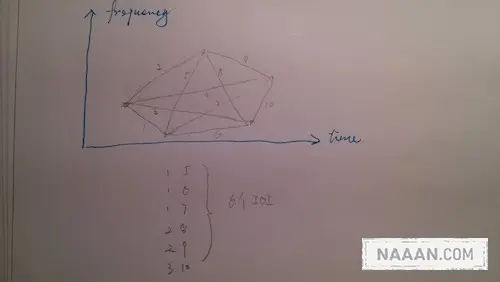
匹配和选择
服务端的样本分析是把歌曲拆成 60 秒的片段进行的,相邻片段有 50% 重叠 (看图),目的是为了防止时长比较高的歌会有更高的得分,同时防止跨界的样本损失太多

在一个直方图里纪录 hash 的匹配次数,直方图一个维度是匹配次数,另一个维度是 hash 在歌曲中发生的时间 比较所有 hash(手机的样本和服务器的),如果吻合就按照时间在直方图中累加,比较完成后选取累计次数最多的那个值作为该片段的得分,最后返回得分最高的。和 Shazam 的方法一样,这种 hash 的匹配会有很大几率配到错的位置上,但是如果样本和服务器的文件真的匹配,时差会很集中,也就是直方图上的那个突出的值会很大。以上就是 echoprint-codegen 的算法了