OpenClaw:一只龙虾如何在 90 天里席卷 GitHub 与 AI Agent 时代
Stars 爆发式增长
目前这个数字已经突破了 31.4 万。
项目关键时间线
| 时间 | 事件 |
|---|---|
| 2025 年 11 月 | 奥地利 iOS 开发者 Peter Steinberger 把 ClawdBot 当作周末项目发布。名字致敬了 Anthropic 的 Claude,并选了龙虾做吉祥物。 |
| 2026 年 1 月中旬 | 项目迎来爆发。72 小时内揽获 6 万 Stars,最高峰时单日增长近万,平均每 10 秒就新增一个关注。 |
| 2026 年 1 月 27 日 | 收到 Anthropic 的商标警告信。因名字过于相似被迫改名 Moltbot。 |
| 2026 年 1 月 30 日 | 再次更名 OpenClaw,保留龙虾主题,定调开源。 |
| 2026 年 2 月初 | 遭遇双重安全危机:爆出 CVE-2026-25253 高危漏洞,同期供应链遭到攻击,ClawHub 上近两成的技能组件被植入恶意代码。 |
| 2026 年 2 月 14 日 | Peter Steinberger 宣布加入 OpenAI。Sam Altman 发推称其为天才。项目交由开源基金会打理,OpenAI 仅作为赞助商,不干涉走向。 |
| 2026 年 3 月 3 日 | Stars 突破 25 万,正式超越 React 成为 GitHub 全球第一大项目。 |
| 2026 年 3 月 6 日 | 腾讯云深圳总部大量员工排队体验本地安装,引发媒体关注。 |
| 2026 年 3 月 8 日 | 深圳龙岗区相关部门针对 OpenClaw 发布使用支持措施的征求意见稿。开源项目直接引动地方政策,极为罕见。 |
创始人:Peter Steinberger
Peter 在苹果开发圈子里小有名气。2025 年 11 月的一个周末,他随手写了个能连通通讯软件的 AI 小工具,这就是 OpenClaw 的前身。
他在宣布加入 OpenAI 时说:
「I’m a builder at heart… What I want is to change the world, not build a large company.」(我骨子里是个建造者。我想改变世界,我不想建一家大公司。)
在不到 5 个月的时间里,他个人在这个项目上提交了 11,684 次 commit。
从一小时原型到全球爆红
根据 Lex Fridman 播客和相关访谈资料,我们可以拼凑出这个项目完整的起源脉络。很快大家也能在 FIZZ 上看到这些深度的梳理。
Peter 之前花了 13 年把 PSPDFKit 做成了装机量十亿级别的企业软件。把公司高价卖掉后,他选择了「退休」。压垮他的原因很常见:十多年的合伙人矛盾和内部消耗。
他原本打算去马德里彻底躺平,结果发现退休生活极其无聊,缺乏挑战甚至让他有了抑郁的倾向。
「当你早上醒来没有任何期待、没有真正的挑战,会非常无聊……当你无聊时,会去刺激自己,可能是毒品……会把你带向黑暗。我不推荐’努力工作然后退休’的计划。」
2026 年 1 月的一个晚上,他决定动手解决自己的需求:打造一个能真正控制电脑的个人助手。他的思路极其简单粗暴:用 WhatsApp 接收消息,传给本地的 Claude Code 命令行,执行完再把结果发回手机。
写完第一版核心代码,他只花了一个小时。
AI 自主解决问题的时刻
几天后在马拉喀什旅行时,他迎来了一个顿悟时刻。他随手给机器人发了段语音。按照原始设定,系统根本不支持语音识别。但机器人的反应出乎意料:它自动读取了文件头,发现是 opus 格式,试图调用本地 FFmpeg 失败后,直接联网调用了 OpenAI 的 Whisper API 完成转录,最后把文字发了回来。
整个过程耗时 9 秒。Peter 回忆说,他根本没写过这部分逻辑,完全是 AI 自己想出的解题路径。那一刻他确信,自己造出的已经是一个能自主解决问题的系统。
命名风波:OpenCloud → Clade → Moldbo → OpenClaw
OpenClaw 这个名字来得并不容易。
最早它叫 OpenCloud,理所当然地遭到了云服务商的抗议。改名叫 Clade 后,又收到了 Anthropic 法务团队「友善但紧迫」的改名要求。
最惊险的一次发生在准备改名为 Moldbo 时。由于消息提前走漏,各平台的账号和域名瞬间被币圈机器人抢注,甚至连他个人的 GitHub 账号都险些被劫持。Peter 当时差点直接删库放弃,最后靠内部朋友紧急介入才拿回控制权。最后,他索性直接去问 Anthropic,敲定了 OpenClaw 这个名字。
加入 OpenAI:在 Meta 与 OpenAI 之间
OpenClaw 爆红后,几乎所有大 VC 和大厂都找到了 Peter。他的选项很清晰:
| 选项 | 描述 | PETER 的态度 |
|---|---|---|
| 自己继续做 | 宁静生活,不融资 | 第一选择,但太孤独 |
| 成立公司融资 | 可能融资数亿美元 | 不想重蹈 13 年覆辙 |
| 加入大厂 | 项目保持开源,加入某家公司 | 最终选择 |
两次关键对话
与 Zuckerberg(Meta):
Mark 在 WhatsApp 上约他,「现在能打吗?」Peter 回复「等我先写完代码」,Zuck 说「好」。Peter 的评价:「他能理解,这就是一个好的开始。」两人随后争论了 10 分钟 Codex vs Claude Code 哪个更好。
与 Sam Altman(OpenAI):
通过 OpenAI 内部人员接触。Peter 说 OpenAI 在 Codex 方面的工作让他有情感认同。
最终决定: 2026 年 2 月 14 日,Peter 宣布加入 OpenAI。Meta 出价更高,但 Peter 选择了 OpenAI。他的原则是:「为了乐趣和影响力,金钱在其次。」
项目移交开源基金会运营,OpenAI 是赞助商之一,但不控制项目方向。Sam Altman 亲自发推欢迎,称其为「genius」。
一个激进的预测:80% 的 App 会消失
在 Lex Fridman 访谈中,Peter 提出了一个激进的预测:
「80%的 app 会消失。为什么我需要健身 app?我的 Agent 已经知道我的饮食决策,它会自动追踪……只有真正有传感器的 app 才能活下来。」
他对 AI 未来的完整图景:
- 短期(1 至 2 年): Agent 取代大量重复性软件使用,日历、邮件、任务管理类 App 首当其冲。
- 中期(3 至 5 年): Bot to Bot 经济出现。你的 Bot 联系餐厅 Bot 进行谈判,Bot 雇用人类执行线下任务(打电话、排队),人类变成 Bot 经济的「执行端」。
- 长期(5 年以上): 专业化智能体生态形成。就像人类社会的专业分工,每个 Agent 专注某个领域,协作完成复杂任务:
仔细观察现在的趋势,很多产品已经开始在底层逻辑上区分「人类用户」和「智能体用户」。我前两年就下过一个谬论,或许未来的产品界面根本就不重要,因为那些 UI 全是给 AI 准备的。
ChatGPT 与 OpenClaw 的根本区别
一句话总结:ChatGPT 是顾问,OpenClaw 是员工。
顾问的工作模式是「你问,他答」。员工的工作模式是「你交代任务,他去执行,期间自己解决问题,完成后向你汇报」。
| 维度 | CHATGPT | OPENCLAW |
|---|---|---|
| 交互模式 | 你问它答(被动响应) | 自主执行任务(主动行动) |
| 运行环境 | 网页/App(每次都要打开) | 自托管服务器,24/7 在线 |
| 消息平台 | 只有 ChatGPT 自己的界面 | 接入 20+平台(WhatsApp/Telegram/飞书/钉钉/QQ 等) |
| 可扩展性 | GPTs 商店(受 OpenAI 限制) | ClawHub 技能市场(13,729 个 Skills,MIT 开源) |
| 数据控制 | 数据在 OpenAI 服务器 | 完全本地,你拥有所有数据 |
| 模型选择 | 仅 GPT 系列 | Claude/GPT/DeepSeek/Gemini/Ollama 本地模型 |
| 记忆能力 | 会话结束记忆消失(需要付费才有限记忆) | 四层持久记忆系统(SOUL/TOOLS/USER/Session),长期保留 |
| 成本 | $20+/月订阅,受限于使用配额 | 自付 API,按需计费,本地模型可完全免费 |
| 开源 | 闭源 | MIT License,完全开源,可自己改代码 |
围绕 OpenClaw 的新生意
很多人安装完成之后不知道干什么,就看个新闻,抖音上很多人说 openclaw 可以赚钱。
有人建了个叫 TrustMRR 的网站,通过 Stripe 接口实时统计这帮人的收入。目前上面有 167 个项目,近一个月总收入超过 38 万美元,最头部的单月能净赚十万。
点开列表你就会发现,他们卖的全是一键部署服务、代理托管和使用教程。
每一次技术浪潮,最先赚到钱的都不是挖金子的人,是卖工具、卖教程、卖”帮你用起来”服务的人。

https://trustmrr.com/special-category/openclaw
记忆:AI 时代真正的护城河
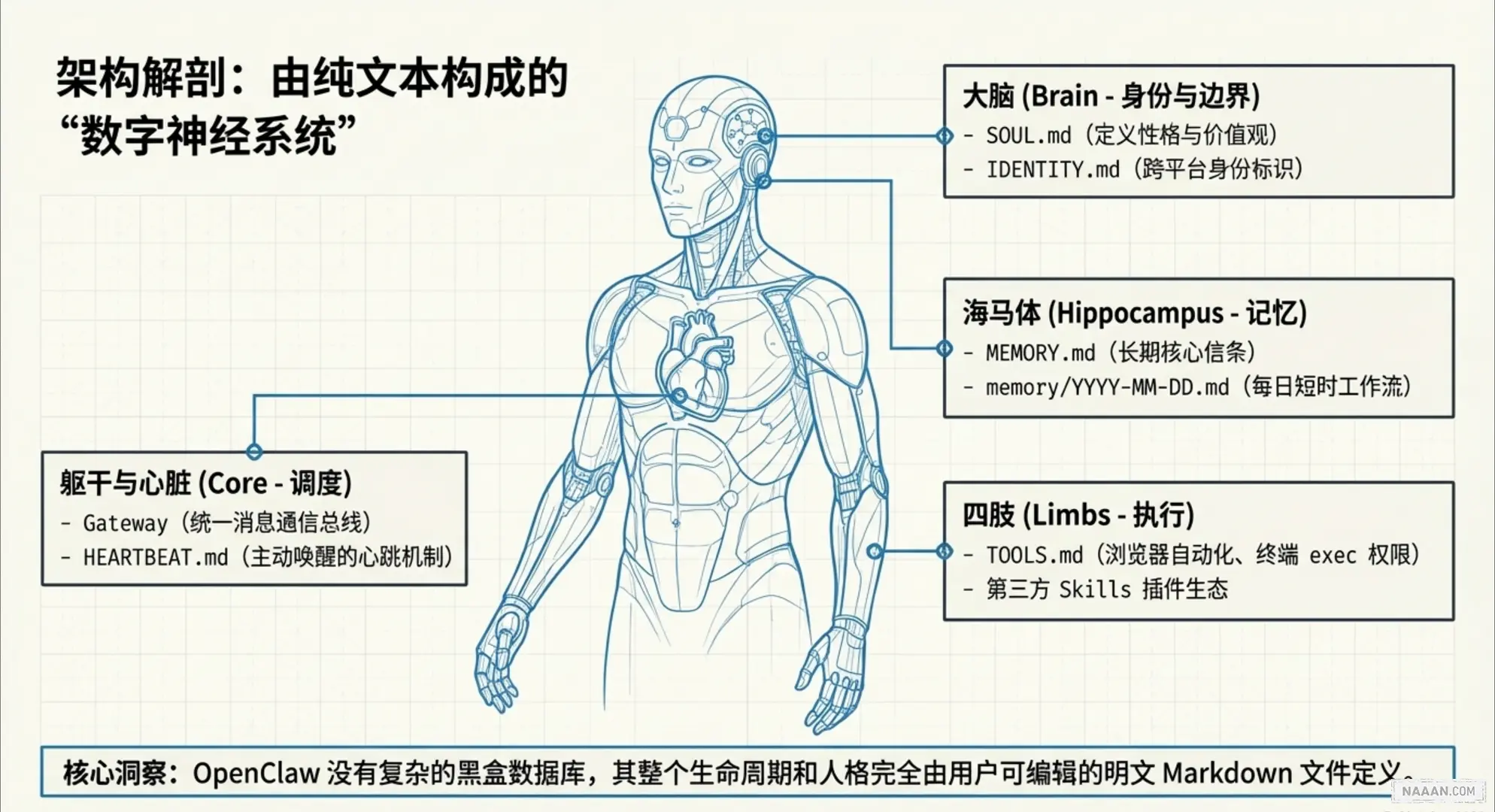
现在行业里都在盯着推理能力和跑分看。但抛开这些技术狂热,大模型迟早会像水和电一样,变成随处可见、价格低廉的基础设施。到那个时候,真正能留住用户并建立商业壁垒的其实只有「记忆」。
如果以后每个人都有 AI 秘书,那么决定它是个普通工具还是贴心伙伴的关键,就在于它有多懂你。它得习惯你的代码命名方式,记住你写文档的排版偏好,甚至得想起你上周五对某个项目进度的抱怨,然后主动帮你跟进。没有记忆的系统每次启动都在面对陌生人,只有存下了长期上下文的系统,才算得上私人助理。
但在实际工程中,这件事很难办。像 OpenClaw 这种全天候运行的智能体,只要一启动就会消耗海量的上下文 Token。
把所有历史记录全塞给模型并不现实。这会带来昂贵的账单,还会让模型的注意力分散。在几十万字的窗口里,模型往往只能记住开头和结尾,却把中间的关键细节丢了。
目前开发者最头疼的,就是怎么规范记忆格式以及如何有效压缩数据。
现在主流的做法是 RAG 配合向量数据库。这种方案挺粗糙的。它只是把对话和文档切碎了扔进库里,用的时候再按相似度捞出来。这种靠暴力检索找出来的碎片只有字面联系,缺乏逻辑连贯性,也理解不了用户的真实意图。这顶多是个资料库,算不上记忆。
接下来的技术重心,大概率会转向结构化的分级记忆。系统需要像人脑一样去整理信息。
比如当前写的代码属于随时待命的工作记忆。主人习惯用 Python 这种信息,应该被提炼成永久的语义记忆。至于某天下午订外卖时的纠结过程,这种情景记忆要么阅后即焚,要么定期打包。
虽然有些厂商推出了上下文缓存来降低成本,但这只是解决了存储层面的问题。如何把信息压缩、提炼,最后构建出一张高精度的用户知识图谱,这依然是一个巨大的机会。
参考资料:
【杨彧鑫 AI】OpenClaw 蓝皮书-1.0.0 版