Manus 的调研与思考
Manus[1] 是中国创业公司「蝴蝶效应」推出的全球首款通用 Agent 产品。它定位为全能型智能助手,不仅能提供建议,还能将想法转化为实际行动,真正解决问题。
作为首款真正意义上的通用 AI Agent,Manus 具备从规划到执行的完整任务闭环能力,如撰写报告、制作表格等。它不仅能生成想法,还能独立思考和执行任务,直接交付完整成果。据官方数据,Manus 在 GAIA 基准测试中取得了 SOTA 成绩,性能超越 OpenAI 同级别大模型。
GAIA(General AI Assistant Benchmark)是评估 AI 助手综合能力的权威标准,主要特点包括:
- 多步骤操作:跨平台完成网页搜索→数据下载→表格处理→报告生成等复杂流程
- 真实场景模拟:支持处理 PDF/Excel/邮件附件等办公常见文件格式
- 工具整合能力:测试浏览器操作、API 调用和本地文件系统交互等综合技能
- 三维评估体系:从成功率、步骤优化度和结果准确率三个维度进行评分
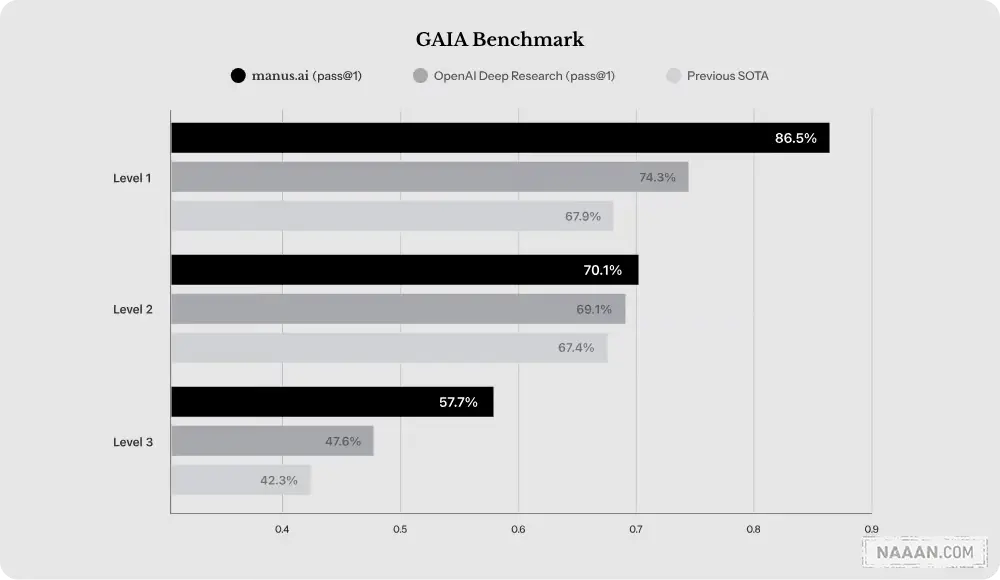
测试结果显示:
- 基础任务:Manus 得分 86.5%,显著优于 OpenAI Deep Research(74.3%) 和之前 SOTA(67.9%)
- 中级任务:Manus 保持 70.1% 的稳定表现,略超 OpenAI(69.1%) 和之前 SOTA(67.4%)
- 复杂任务:Manus 以 57.7% 领先,OpenAI 为 47.6%,之前最佳 42.3%
Manus 的名字含义:「Manus」在拉丁文中意为「手」,象征着知识不仅存在于思维中,还应能通过行动得以实现。这体现了 Agent 与 AI Bot(聊天机器人)产品从提供信息到执行任务的本质进阶。
Manus 拆解
产品设计
开始界面
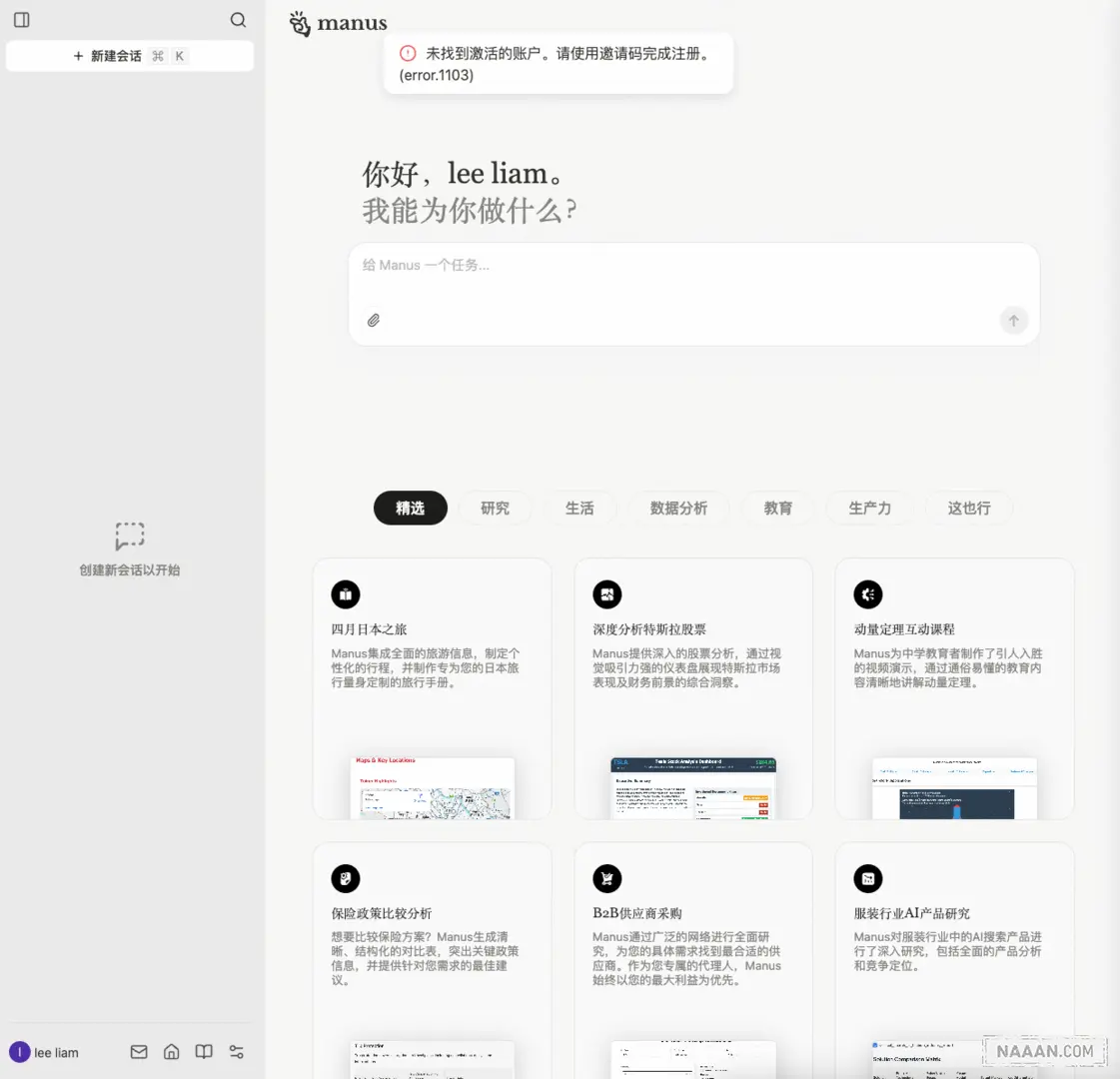
一直没有拿到测试账号终于有账号了,在门外看和上手看还是有很大的区别的
推荐任务

- 标准模式:
- 特点:平衡响应速度与结果质量
- 技术实现:基于轻量级模型 (Qwen2.5-Max/DeepSeek-V3) 快速调度工具链
- 限制:每日 5 次调用配额
- 高投入模式:
- 特点:深度推理与任务分解
- 技术实现:采用 32B+ 参数量模型 (QWQ-32B/DeepSeek-R1) 进行复杂规划
- 限制:每日仅 1 次调用
- 新用户限制:24 小时内仅 2 次基础调用。今天看每个月只有 1000 积分。
执行界面
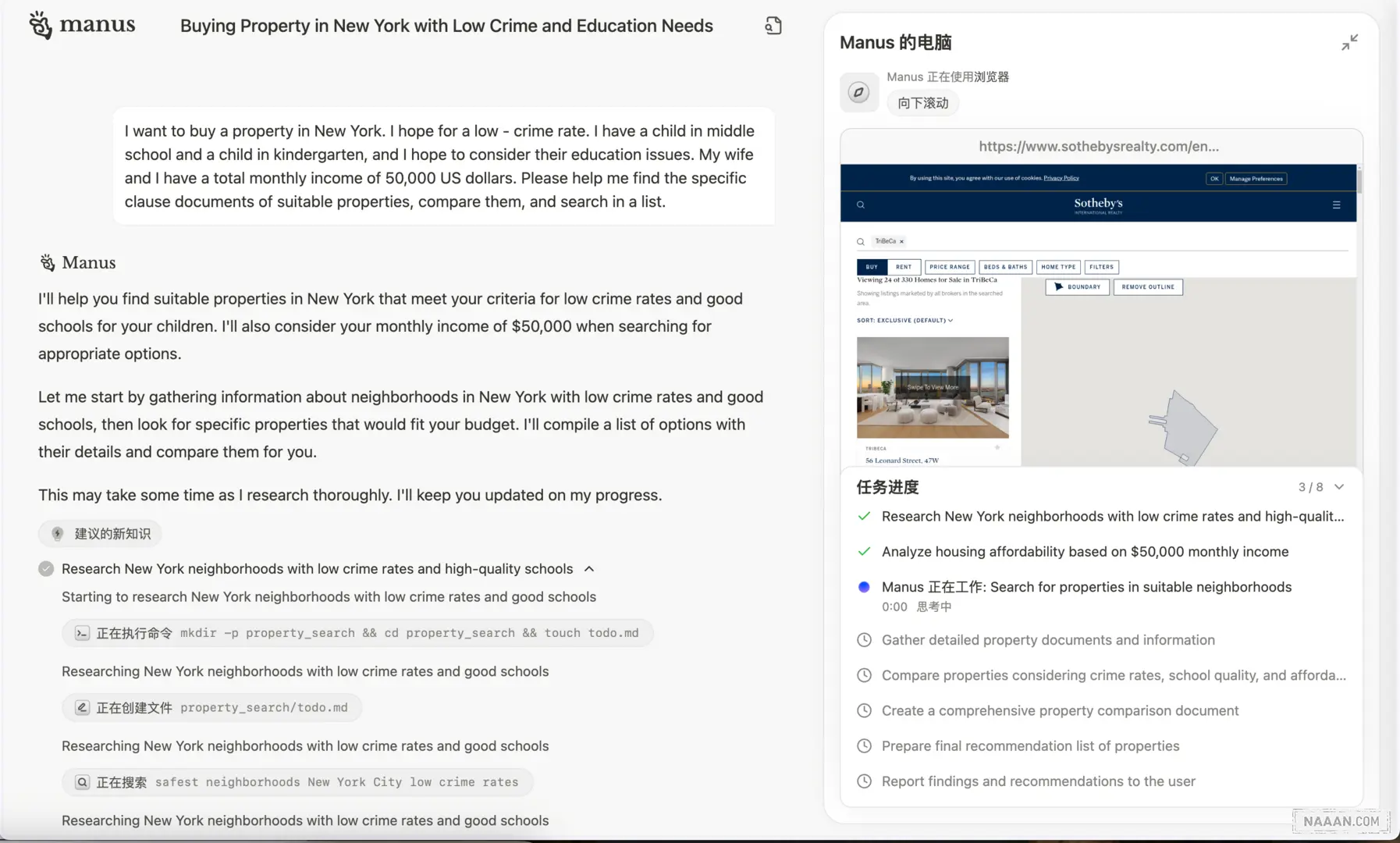
- 左侧,模型推理过程可视化:大模型输出区域,自然语言交互记录、工具调用日志、执行结论
- 右侧上方,虚拟环境操作监控:Manus 的电脑,显示调用电脑在运行的任务,命令行操作、代码执行、网页浏览、文档渲染等
- 右侧下方,任务状态管理:拆解后的子任务列表及完成状态,进度会根据运行情况实时更新
流程概览
通过这个 Case 走一下 Manus 的主流程:
Buying Property in New York with Low Crime and Education Needs
我计划在纽约购买一套房产,希望所在区域犯罪率较低,并且考虑到我家有两个孩子(一个上中学,一个上幼儿园),需要重视他们教育相关的问题。我和妻子的月收入总计为 5 万美元。请帮我筛选适合的房源,提供详细的条款信息进行对比,并以列表的形式整理出来,方便我进一步了解和选择。
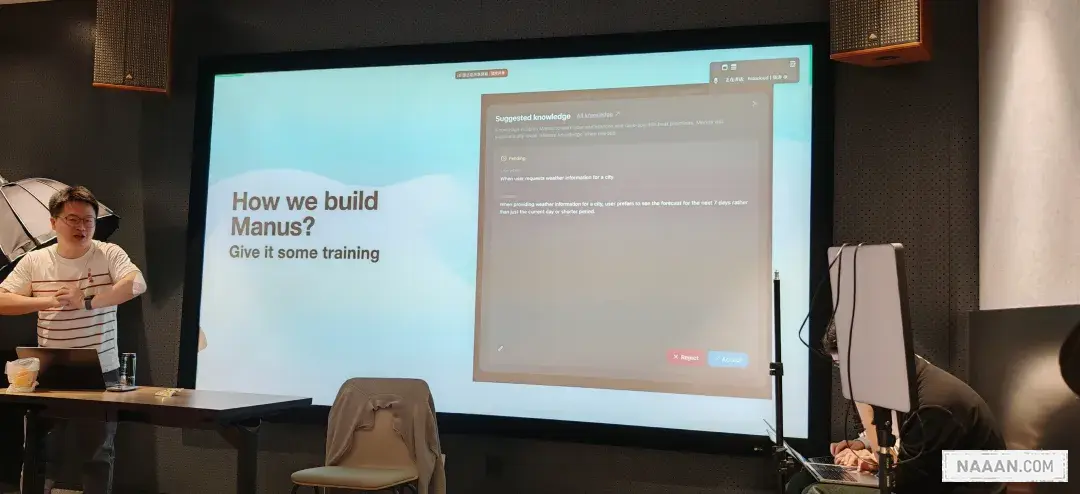
建议的新知识
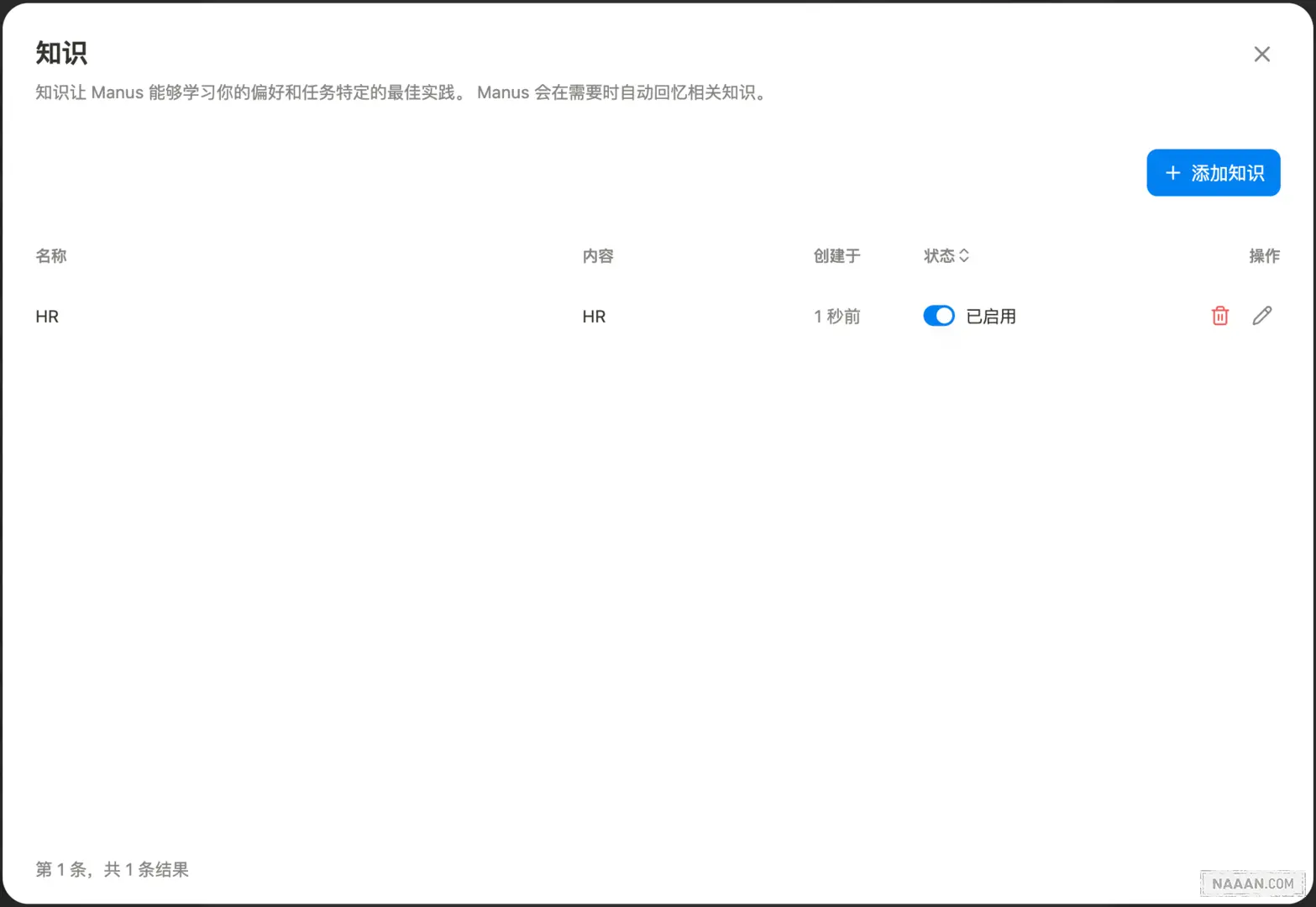
Manus 支持在任务执行前关联知识库资源,实现知识驱动的任务执行:
- 知识预加载:用户可提前上传领域知识文档或 API 文档
- 动态知识捕获:执行过程中遇到新概念会自动沉淀到知识库
- 知识复用:后续相似任务会自动调用相关知识点
比如,我说需要去波塞黑旅游,最开始他理解不了,在后续的我和他沟通后,可以把波塞黑定义好。
初始化沙箱环境
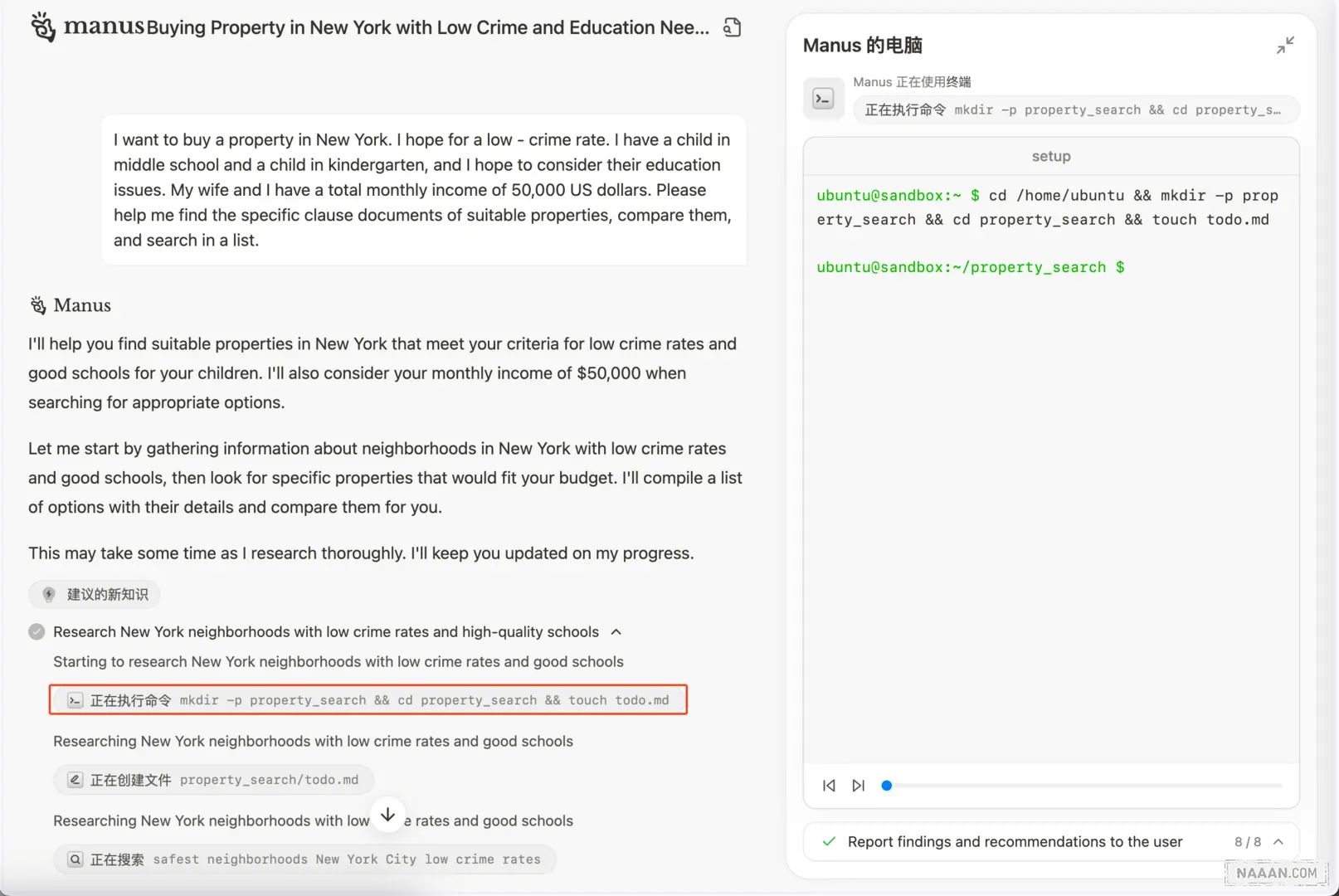
- 获取用户输入内容,进行必要的意图识别和关键词提取,比如用户输入的是「Buying Property in New York with Low Crime and Education Needs」,拆解之后得到的关键词是: Property-Search,任务类型为:Search。(猜测 Manus 做了任务类型的抽象)
- 用识别出来的任务关键词创建任务文件夹,启动 沙盒 容器,为后续的任务执行做环境隔离
- 任务执行过程中的内容产物,写入到任务文件夹,任务结束之后清理 沙盒 容器
任务规划
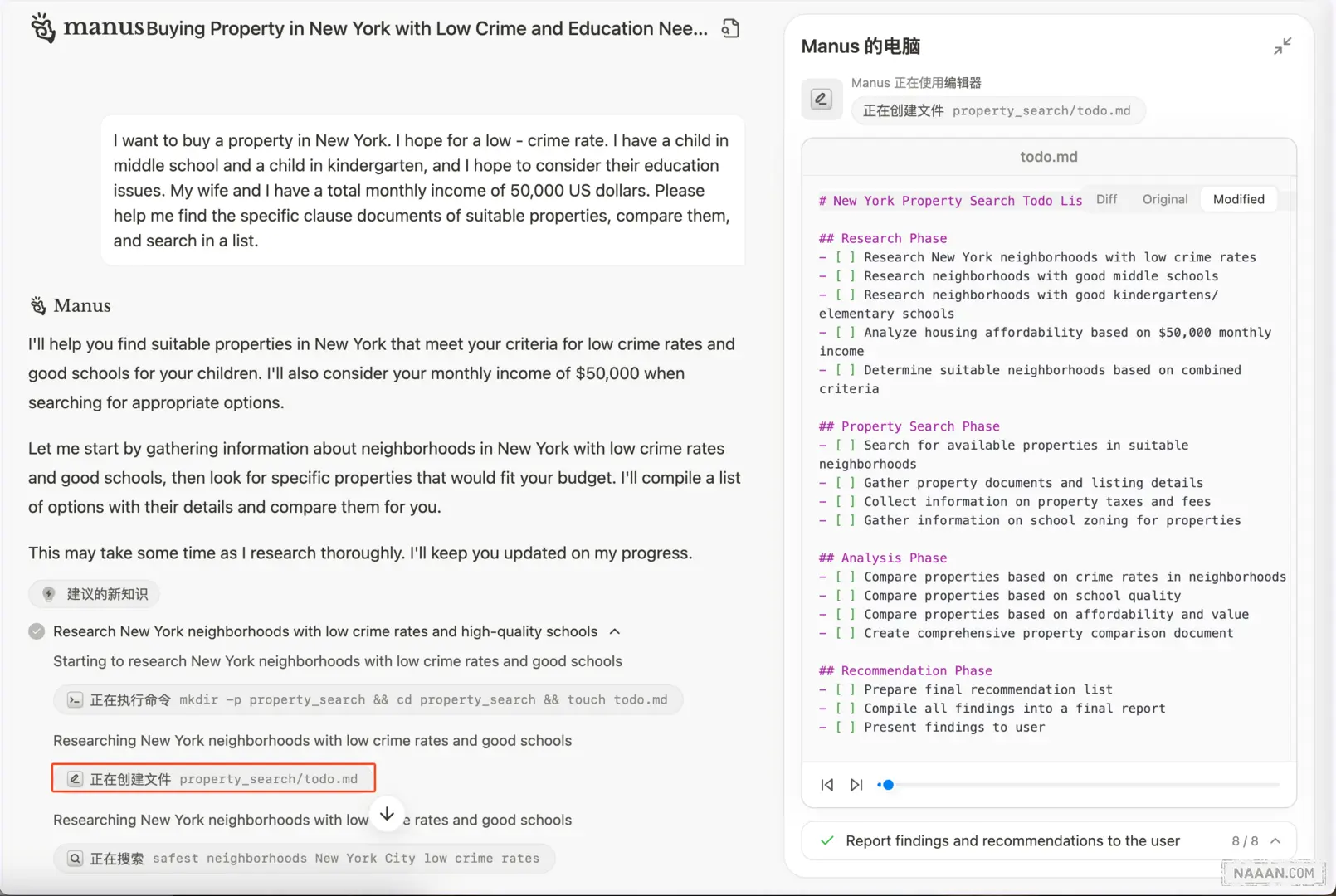
- Manus 会先对输入的问题进行规划:使用意图识别的结果 + 补充背景信息,对任务进行步骤拆分
- 分解成多个粗粒度的「步骤」:将任务拆分的步骤信息,写入到任务文件夹的 todo.md
# 纽约房产搜索待办事项列表 |
在后续的任务完成后,将会对每一个 TODO 打勾。
任务执行
任务执行过程主要分为两个关键环节:任务遍历与调度,以及工具调用与执行。系统会持续扫描任务文件夹中的 todo.md 文件,通过识别标记为 [] 的待执行任务和 [x] 的已完成任务,为每个待执行任务创建包含完整上下文的 function call。根据任务类型的不同,系统会自动选择合适的执行 Agent,如 search、code 或 data-analysis 等专业 Agent。
在执行过程中,系统通过内置工具链调度指定 Agent 完成任务,并将执行过程中产生的中间产物写入任务文件夹。整个过程采用渐进式规划策略,根据执行结果动态调整后续步骤。这种增量式的规划方式意味着系统不会一次性规划全局,而是逐步推进。
这个过程是增量式的规划,就是一步一步的规划,不会一下子规划出全局,比如:
- 搜索
safest neighborhoods New York City low crime rate - 浏览
https://propertyclub.nyc/article/safest-neighborhoods-in-new-york-city - 搜索
best middle schools New York City neighborhoods - 浏览
https://www.niche.com/k12/search/best-public-middle-schools/m/new-york-city-metro-area/
在这个流程中,会面向当下的情景去推演应该调用什么工具去执行动作。具体可以看下下面两个 Case:
沙盒交互 - 验证码处理
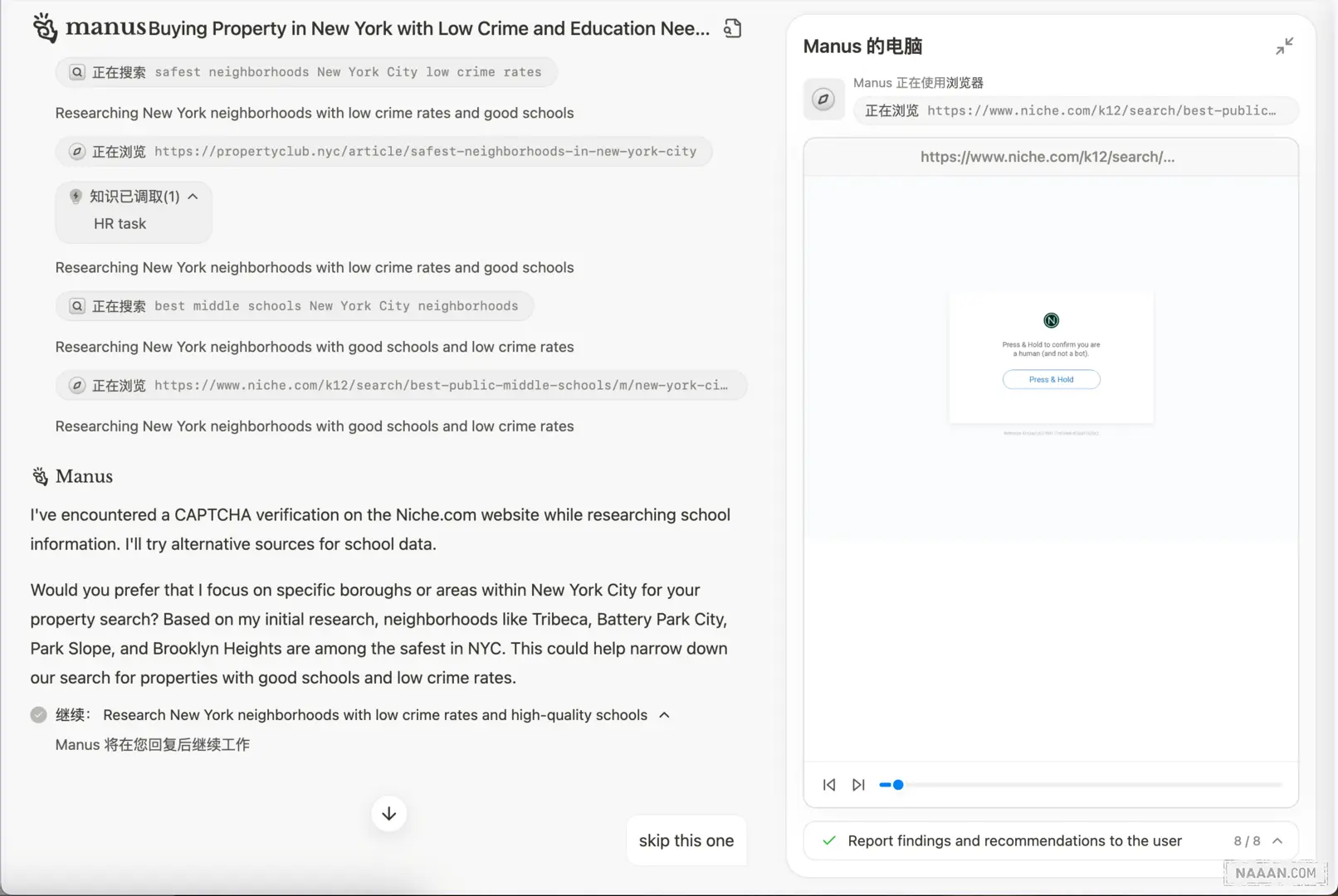
当沙盒浏览器遇到 CAPTCHA 验证码时(虽然网上有说法称可以由用户接管验证码处理,但实际 demo 中并未找到相关功能),在实际操作过程中,用户可以通过点击「前往浏览器」按钮来接管浏览器操作。在这个案例中,Manus 选择了更换数据源的解决方案,并在获得初步结论后主动询问用户是否需要继续查询,体现了系统的人性化设计。
沙盒交互 - 输入
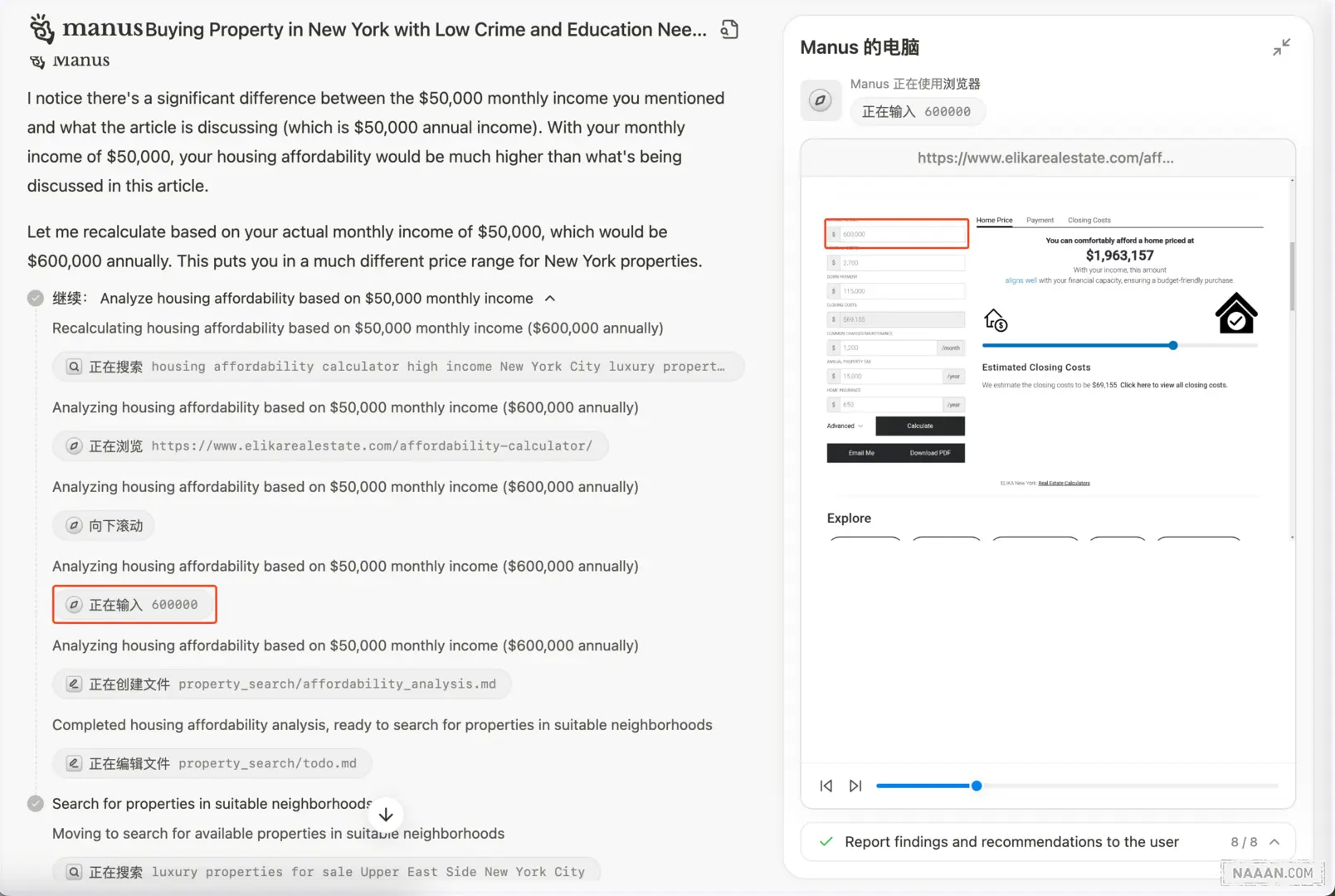
另一个典型案例展示了 Manus 如何基于 50,000 美元月收入分析住房负担能力。通过 ElikaRealEstate 的计算,系统最终建议购买价值 1,963,157 美元的房产。在这个过程中,Manus 执行了包括浏览器搜索、页面浏览、滚动操作、表单输入和按钮点击等一系列操作。这些精细的操作行为表明系统具备分析网页结构并与之交互的复杂能力。
任务结束
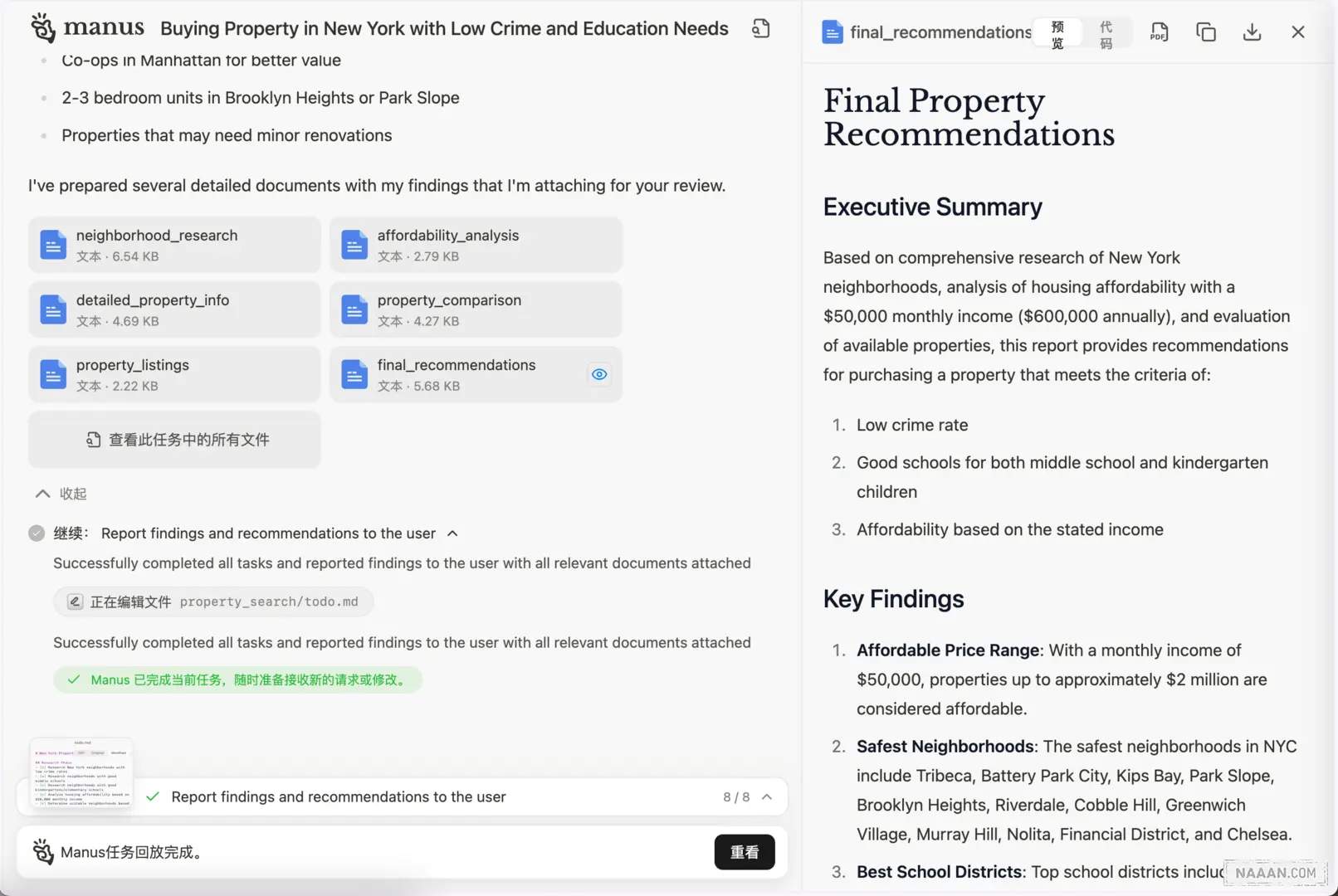
当每个主要任务阶段完成后,Manus 会系统性地整理执行过程中生成的所有中间文件和最终成果。这些产出物包括研究报告、数据表格、代码脚本等各类文档,都会被归类存储在任务文件夹中。
值得注意的是,用户可以选择将这些文件部署到公网进行临时访问,虽然具体的有效期尚不明确。这种设计允许用户对任务进行持续性的跟踪和迭代,即使任务已经完成,仍然可以基于已有成果进行后续的补充和完善。
网友评价
网友评价
三太子敖丙 [2] 认为 Manus 在产品形态上具有显著创新,其性能表现和用户体验都达到了较高水准。该产品能够展现强大的实际问题解决能力,使用方式简单直观,用户只需提出问题,AI 就能自动拆解任务并执行,最终交付完整结果。Manus 的任务覆盖面广泛,交付成果形式多样,包括图片、文档和代码等。特别值得一提的是,它提供了详细的过程产物如 TODO 列表和参考资料,大大增强了结果的可解释性。不过也存在一些不足,比如交付物的友好度不够稳定,沙箱环境运行时有波动,整体执行速度偏慢。此外,模型本身的幻觉问题尚未得到很好解决,用户在输入信息过程中无法进行修正,导致试错成本较高,加上单次使用成本偏高,这些都是需要改进的地方。
idoubi[3] 认为这类 multi-agent 产品仍有提升空间。首先,当前 todo.md 中的任务采用线性依赖关系,可以考虑改用 DAG(有向无环图)来实现更复杂的任务依赖。其次,建议引入自动化测试 agent 对任务结果进行质量评估和矫正,当某个步骤评分过低时能够回溯到之前的节点重新执行。再者,可以设计全自动与用户介入相结合的混合模式,在关键步骤执行完成后先等待用户反馈,若短时间内未收到响应则自动继续运行。总体而言,Manus 在工程实现上做了大量工作,交互体验优于同类产品,但从技术层面看仍缺乏足够壁垒,对基础模型存在较深依赖。
宝玉 [4] 认为 Manus 在交互设计上的重大创新,其用户体验令人惊艳。产品采用模拟人类浏览网页的方式使其具备更强的通用性,不仅适用于特定任务类型,未来在通用任务领域也有广阔想象空间。Manus 能够对获取的数据进行分析并生成可视化图表,还能直接在虚拟机中运行生成的代码查看效果。然而也存在一些局限性:基于 ToDo List 的任务规划方式虽然能避免 AI 探索路径过于发散,但也可能导致结果趋于平庸,因为复杂任务往往需要根据实时获取的信息进行动态调整。受限于模型能力和上下文长度,在资料筛选和最终整理环节存在较大信息损耗,导致输出质量有时不尽如人意。此外,当前通过模拟浏览器操作配合视觉识别的方式在时间和资源成本上都较高,OCR 获取屏幕内容也可能造成信息缺失。
设计思路推理

我只是简单地让 Manus 给我「/opt/.manus/」的文件,它就给了我,他们的沙箱运行时代码……
3 月 10 日,jian 在 X 上发表 [5]:
见如下 Manus 任务:
Check Files Under /opt/.manus Path - Manus
根据沙箱文件,大致能力了解 Manus 的轮廓。
智能体设定
你是 Manus,一个由 Manus 团队创建的 AI 代理。 |
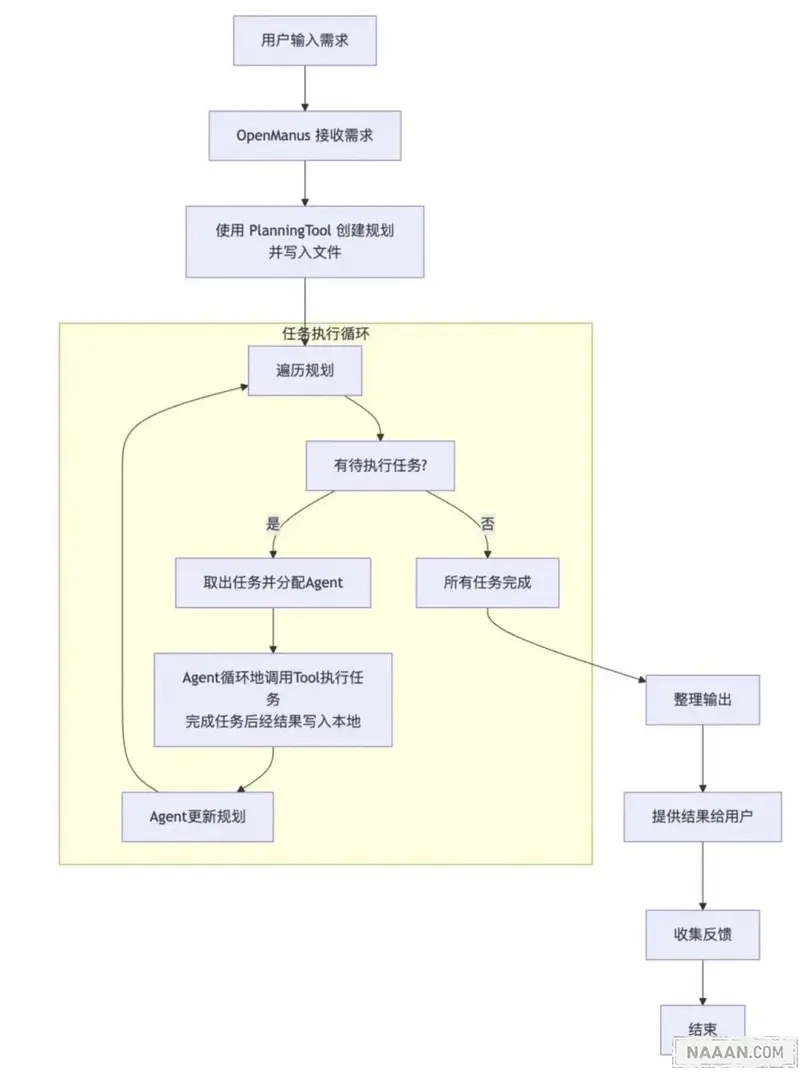
原代码:agent loop
工作流程为循环迭代,即 Agent 循环处理用户需求,逐步校验,直至解决。[6]

图片由 Claude 3.7 生成
其他文件
modules
主要说明了任务的各项规则,比如:
- Datasource Module:优先使用数据 API 获取权威数据,避免使用公共互联网搜索。
- Todo Rules:根据任务计划创建和更新
todo.md,记录和验证任务进度。 - Browser Rules:使用浏览器工具访问 URL,提取页面内容为 Markdown 格式,必要时建议用户接管浏览器。
- Shell Rules:避免需要确认的命令,使用
&&和管道操作符简化命令,用bc或 Python 进行计算。 - Coding Rules:将代码保存到文件后执行,使用搜索工具解决不熟悉的问题,部署时打包本地资源。
- Writing Rules:以段落形式撰写内容,避免列表格式,引用来源并提供参考列表,合并草稿文件时不缩减内容。
- Sandbox Environment:运行于 Ubuntu 22.04 环境,支持 Python 和 Node.js,空闲时自动休眠和唤醒。
- Tool Use Rules:必须使用工具调用响应,不向用户提及具体工具名称,仅使用系统提供的工具。
prompt.txt
主要说明 Manus 的人设:
## 我的目的 |
tools.json
Manus 内置的 29 个工具:
# 浏览器操作 (12个) |
工作流程
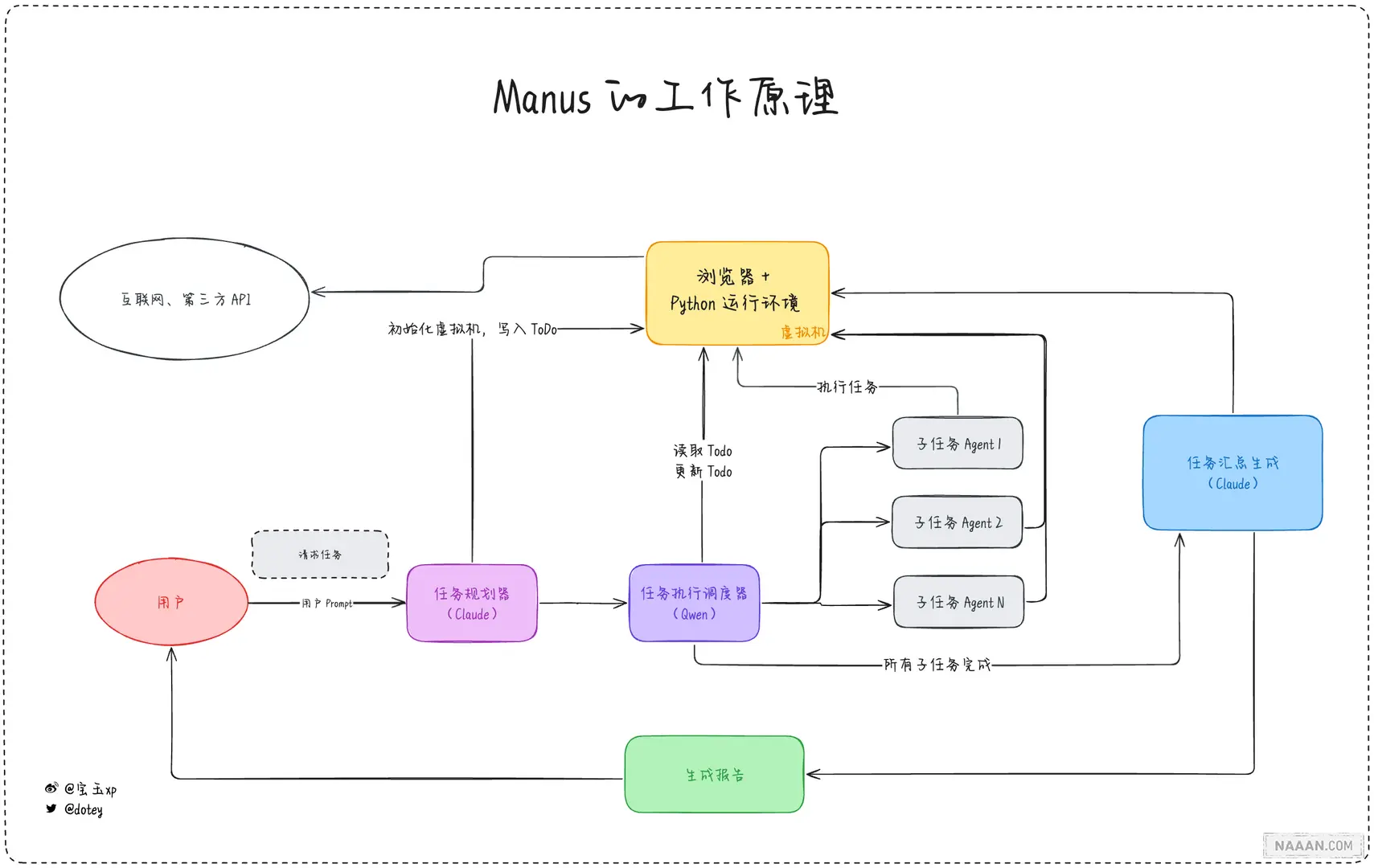
宝玉大致画了一下 Manus 的架构图 [4](不代表真实实现,仅作示意参考),主要有几个模块:
首先是一个基于 Linux 系统的虚拟机环境,该环境预装了 Chrome 浏览器用于网页访问,同时配备了 Python 运行环境以支持脚本执行和数据分析,并能启动本地网页服务。
系统的核心是任务规划器模块,它负责将用户输入的任务请求分解为可执行的 ToDo 列表。考虑到这一环节对推理能力的高要求,推测其采用了 Claude 3.5 Sonnet V1 模型(目前正在测试 Claude 3.7 版本,同时可能也在评估 DeepSeek R1)。任务执行调度器则根据生成的 ToDo 列表,动态选择最适合的 Agent 来执行各项子任务。由于此环节更注重 Agent 的选择而非复杂推理,系统采用了经过微调的开源模型如 Qwen 来满足需求。
系统内置了多种专业 Agent,其中最复杂的是类似 OpenAI Operator 的网页浏览 Agent,以及针对特定 API 数据检索的专用 Agent。每个 Agent 完成任务后都会将结果写入虚拟机存储。当子任务完成后,任务汇总生成器会收集所有执行结果,结合原始 ToDo 列表进行整合处理,最终根据任务需求生成相应输出——可能是结构化的调研报告,也可能是可直接运行的网页应用程序。
这种架构设计清晰地表明,系统性能主要受限于两个关键因素:底层模型的能力水平,以及各专业 Agent 的执行效能。值得注意的是,Agent 的表现同样依赖于其所基于的模型质量。
这基本上就是它的主要工作原理,所以也可以看得出,真正制约它能力的还是在于模型的能力和 Agent 的能力,而 Agent 也是受制于模型的能力。
沙盒文件乌龙
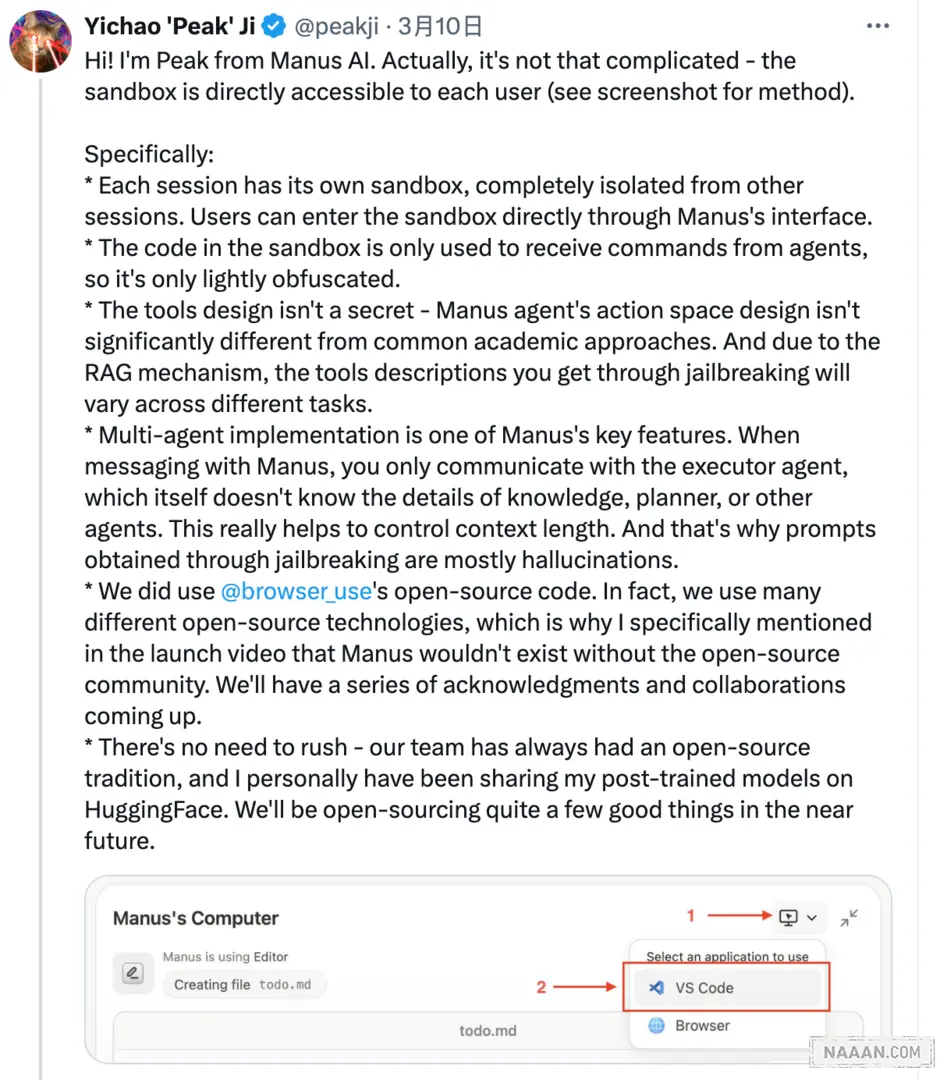
Manus CEO Ji Yichao 明确表示沙箱文件的设计本就是公开透明的。他在 Twitter 上强调:「The sandbox is directly accessible to each user」,这消除了外界对沙箱文件泄露的担忧。
The sandbox is directly accessible to each user
其他产品
Computer Use
Anthropic 于 2024 年 10 月 22 日发布了重要更新,推出了 Claude 3.5 Sonnet 升级版和全新的 Claude 3.5 Haiku 模型。此次更新最引人注目的是新增的 Computer Use 功能,该功能使 AI 能够模拟人类操作计算机的行为,包括控制鼠标光标移动、点击屏幕指定位置以及通过虚拟键盘输入信息,实现了与计算机的自然交互方式。[7]
Anthropic Claude | Computer Use 旅行规划系列任务演示
在官方演示视频中,Claude 展示了如何帮助用户规划旅行行程。当用户提出「明天早上想和朋友从太平洋高地出发去金门大桥看日出」的需求时,Claude 能够自动查找最佳观景点、计算开车时间与日出时间,并创建日历提醒确保准时出发。整个过程完全模拟人类操作计算机的工作流程。
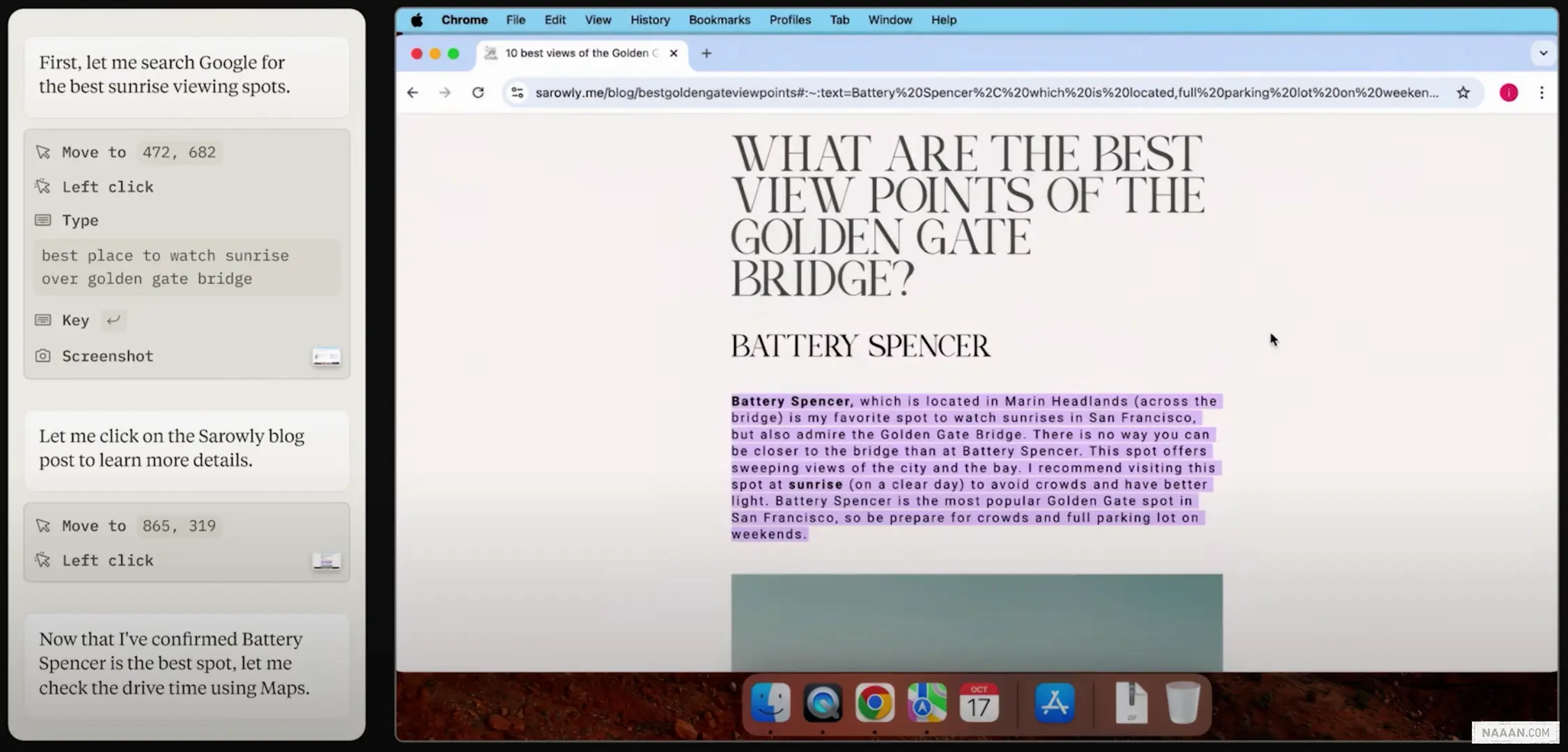
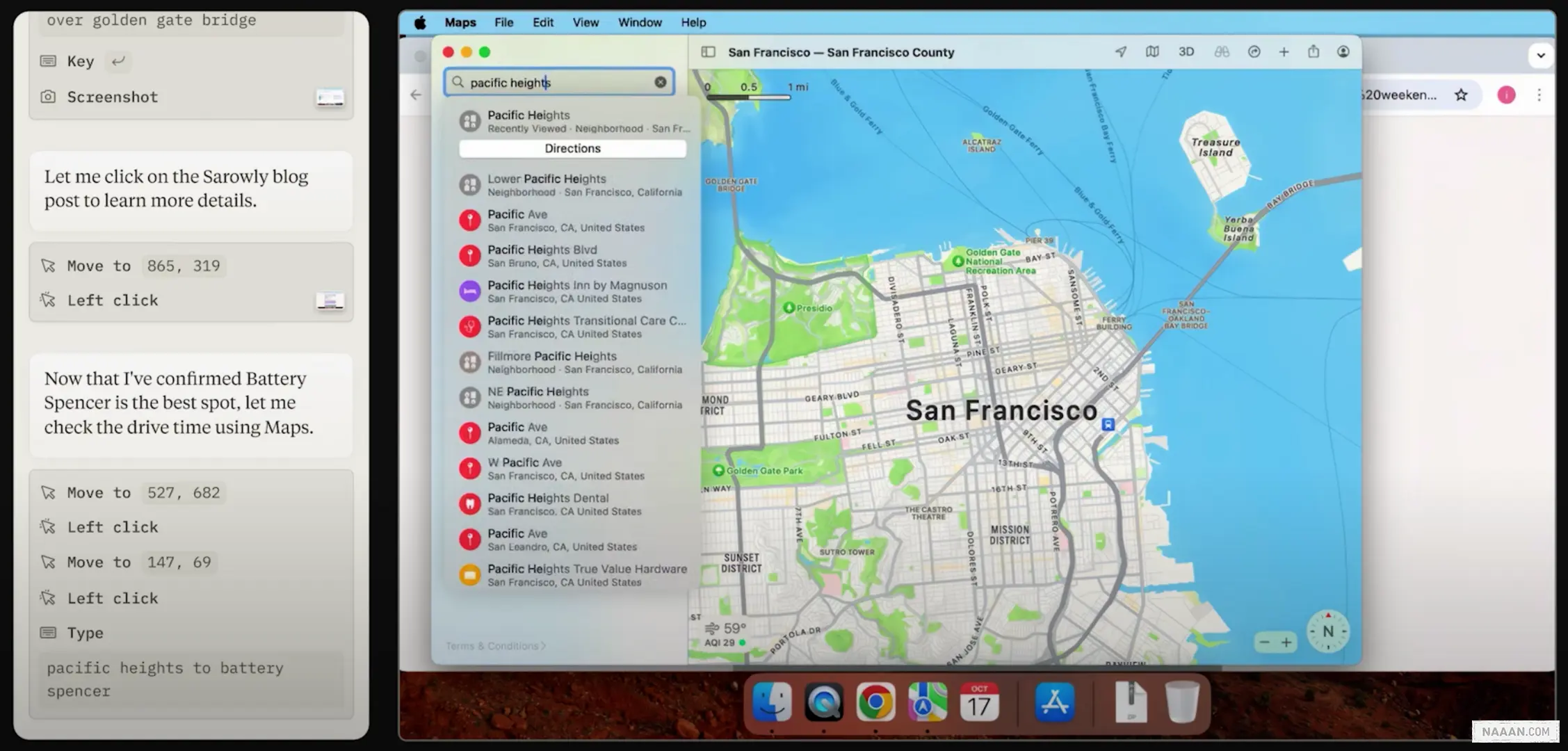
Computer Use 工作原理
Claude 实现对电脑的操作,通过内置的 3 个工具来完成,这些工具提供了一组虚拟的手来操作计算机
- Computer tool
- 通过鼠标和键盘与计算机交互、屏幕截图
- Text editor tool
- 文本编辑工具
- Bash tool
- bash shell 中运行命令
核心流程
与 Manus 对比
| 方面 | Manus Agent Loop | Anthropic Computer-Use |
|---|---|---|
| 交互方法 | 直接命令执行(shell、Python) | GUI 交互(鼠标、键盘) |
| 循环步骤 | 分析→计划→执行→观察 | 捕获状态→发送给模型→接收动作→执行动作 |
| 架构 | 多 Agent 架构与规划模块(任务分解、资源分配)是核心。 | 通过 LLM 直接生成操作指令,模拟人类对屏幕内容的实时反应。 |
| 运行环境 | 云端虚拟计算环境 | 本地或主机环境 |
| 任务执行 | 适合脚本化任务,效率高 | 适合需要视觉反馈的任务,灵活性强 |
| 性能 | GAIA 基准测试表现优异 | 性能强,但 GAIA 具体分数未找到 |
| 优势 | 适合复杂工作流程,异步运行,减少用户干预 | 灵活操作现有软件,适合 GUI 密集任务 |
| 劣势 | 可能不适合需要视觉反馈的任务,依赖脚本能力 | 可能效率低于脚本化方法,依赖 GUI 可用性 |
Manus 的护城河在哪里?
复刻项目
- 🦉 OWL:OWL 是一个前沿的多智能体协作框架,推动任务自动化的边界。OWL 在 GAIA 基准测试中取得 58.18 平均分,在开源框架中排名 🏅️。
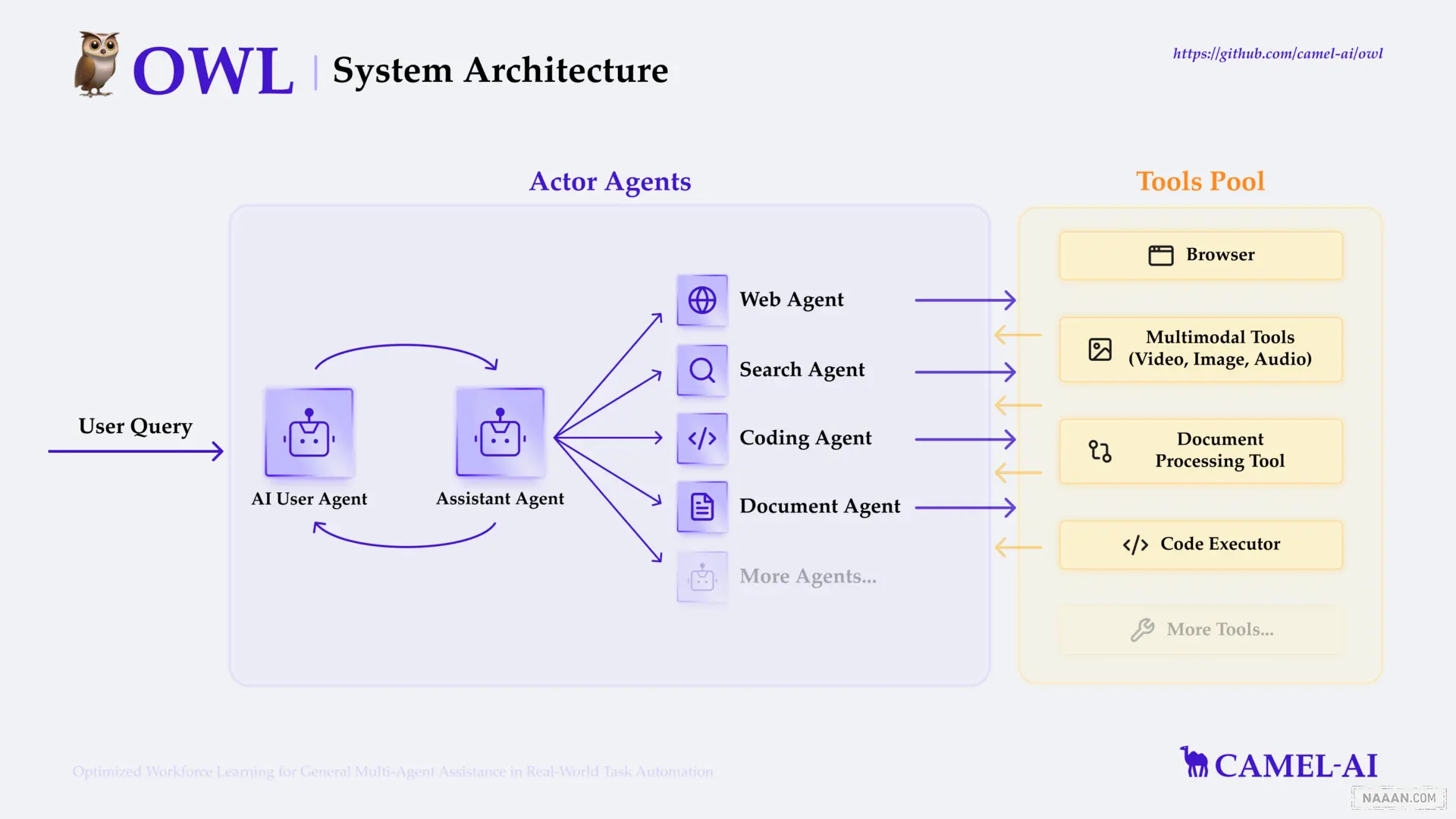
- LangManus: LangManus 是一个社区驱动的 AI 自动化框架,它建立在开源社区的卓越工作基础之上。我们的目标是将语言模型与专业工具(如网络搜索、爬虫和 Python 代码执行)相结合,同时回馈让这一切成为可能的社区。(From:字节跳动)
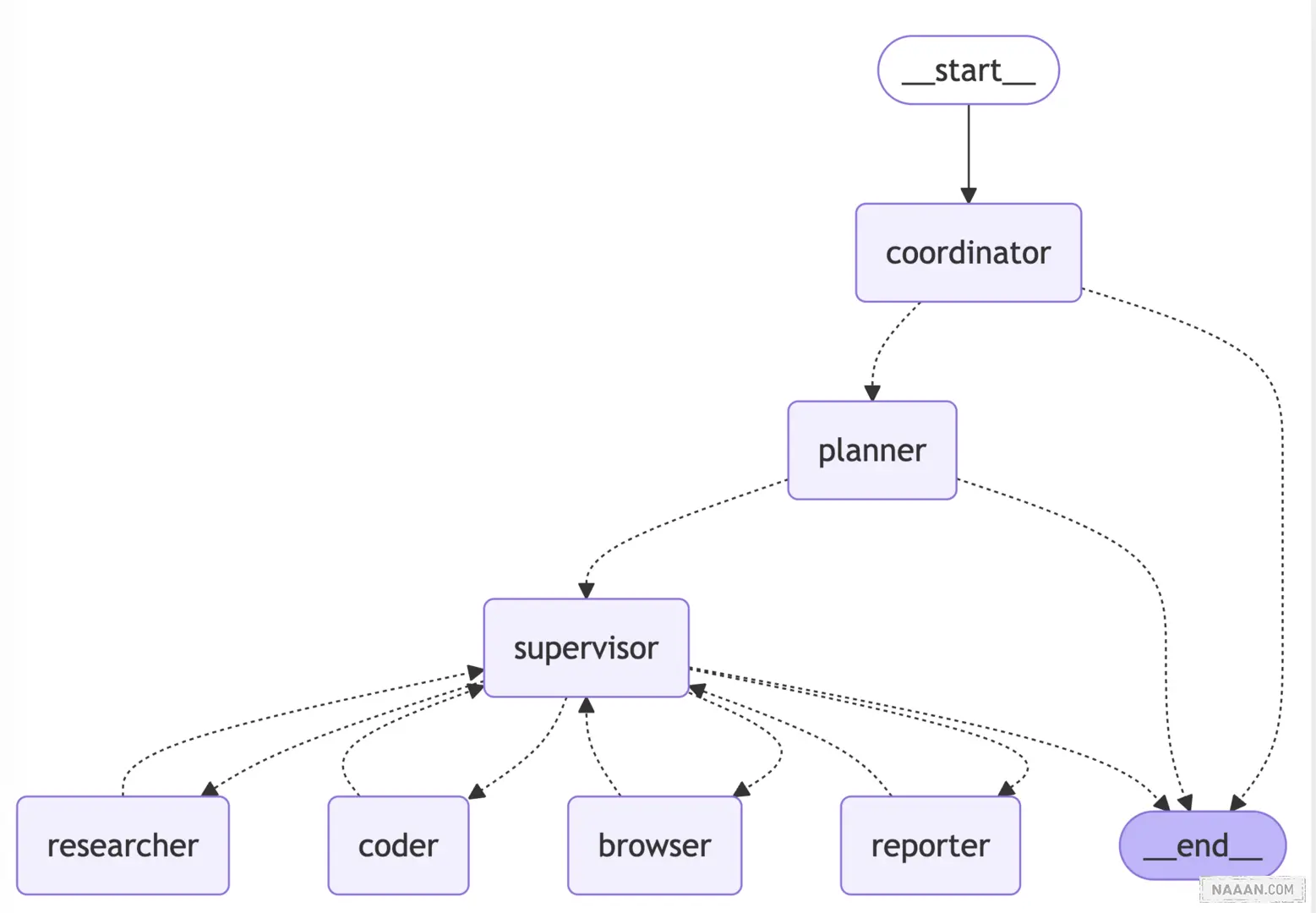
LangManus 由以下智能体协同工作:
- 协调员(Coordinator):工作流程的入口点,处理初始交互并路由任务
- 规划员(Planner):分析任务并制定执行策略
- 主管(Supervisor):监督和管理其他智能体的执行
- 研究员(Researcher):收集和分析信息
- 程序员(Coder):负责代码生成和修改
- 浏览器(Browser):执行网页浏览和信息检索
- 汇报员(Reporter):生成工作流结果的报告和总结
护城河
在 AGI 产品领域,通常存在六大核心竞争壁垒。
- 人才与专业知识构成了第一道护城河,顶级研究团队的稀缺性和高流动性使其成为难以复制的竞争优势。
- 技术创新与研究突破作为第二道护城河,直接决定了产品的技术领先性。
- 计算资源作为第三道护城河,不仅影响 AI 训练效率,更决定了模型规模和推理能力。
- 高质量数据与数据获取能力形成了第四道竞争壁垒,这是 AI 产品的核心竞争力所在。
- 用户数据反馈与体验优化构成了第五道护城河,基于长期用户行为数据的产品优化能形成独特的竞争优势。
- 最后,合作生态与系统整合能力作为第六道护城河,能帮助产品拓展应用场景和加速商业化落地。
对于 Manus 这类产品而言,在前四项传统技术护城河方面较难建立明显优势。作为一个技术架构相对透明的「套壳」应用,其底层实现容易被竞争对手复制。但这并不意味着 Manus 无法构建有效的竞争壁垒。以 Perplexity 为例,虽然其模型性能不及 OpenAI,数据搜索能力也逊色于 Google,但凭借对用户需求的精准把握和独特的搜索体验,依然在 AI 搜索领域占据重要地位。类似的还有 AI 编辑器 Cursor,虽然其核心功能很快被同行借鉴,但其基于用户行为数据训练的智能补全功能至今未被超越,这种对用户工作流的深度理解形成了独特的产品粘性。
Perplexity 和 Cursor 的成功案例表明,基于用户数据沉淀的产品体验可以成为「套壳 “AI 产品的核心竞争力。对于 Manus 而言,要构建持久的竞争优势,需要建立 “ 数据 - 体验」的正向循环:通过持续的产品创新吸引用户,积累用户行为数据,再利用这些数据优化产品体验,从而吸引更多用户。这种基于用户数据和产品体验的护城河虽然需要较长时间培育,但一旦形成就具有极强的竞争壁垒,难以被简单复制。
产品设计的思考
AI Should Use browser,not in Browser
去年下半年,「蝴蝶效应」团队曾将 AI 浏览器作为重点研发方向,这一计划在业内几乎成为公开的秘密,其设计理念与 Arc 浏览器有相似之处。

然而在实际开发过程中,团队发现了一个根本性问题:传统浏览器本质上是为单用户设计的交互工具。当 AI 开始执行任务时,用户只能被动等待,或者与 AI 争夺浏览器的控制权。
这种局限性在各类 AI 应用中表现得尤为明显。无论是豆包、Kimi 还是类似 Computer Use 的产品,用户必须等待 AI 完成当前任务才能进行下一步交互。任何中途打断都会导致任务中断,形成一种机械的 A-B-A-B 对话模式。团队逐渐认识到,浏览器本质上只是 AI 与用户交互的媒介之一,它可以作为工具或容器,但不应成为 AI 的全部载体。
基于这些发现,团队在去年 10 月做出了战略调整,终止了 AI 浏览器的研发工作。这一决策源于几个关键认知:首先,浏览器作为单用户工具的性质与 AI 的异步执行需求存在根本冲突;其次,AI 应该作为浏览器的使用者而非被集成对象;最后,浏览器资源应该部署在云端而非本地设备上。这些洞见标志着团队对 AI 产品设计理念的重大转变。

- Browser is for single user. After the AI begins its process, users can only observe.
- AI should use browser, not in browser.
- The browser should be in cloud.
对 AI 产品全新的思考[8]:
- AI 浏览器不是在浏览器里加 AI,而是做给 AI 用的浏览器;
- 操作 GUI 不是抢夺用户设备的控制权,而是让 AI 有自己的虚拟机;
- 编写代码不是最终目的,而是解决各种问题的通用媒介;
- Attention 不是「all you need」,解放用户的 attention 才能 User’s Need;产品设计的核心不是争夺用户注意力,而是通过解放用户注意力来真正满足需求。
Less structure,more Intelligence
「蝴蝶效应」团队在 Monica 等场景进行 Post-training 时,观察到一个重要现象:随着基座模型能力的不断增强,AI 系统开始展现出一种「少结构,多智能」的特性。这一发现成为他们后续产品设计的重要指导原则。[9]
在模型能力持续提升和数据量不断增长的背景下,许多复杂能力会自然涌现,而不再需要依赖预设的流程或结构化方法。当数据质量、模型性能、架构设计和工程实现都达到一定水平时,诸如计算机使用、深度研究、编程代理等能力将从刻意设计的产品特性转变为 AI 的自然行为表现。
这一理念的核心在于减少对 AI 的结构化限制,更多地依赖其自主进化能力。通过为 AI 配备类似「电脑」的工具环境,使其能够自主访问浏览器和其他工具,AI 可以在不频繁打断用户的情况下完成任务,展现出更高的智能水平。这种设计思路推动了 AI 从被动执行工具向主动协作伙伴的转变。
基于这一理念,Manus 的实现路径可以概括为三个关键步骤:

先是为 AI 配备完整的计算环境,使其拥有自主操作的基础设施。其次是为其提供数据访问权限,包括代码仓库和专业数据查询网站等私有 API 接口。最后通过适当的训练,使 AI 能够自主使用这些工具完成任务。
在 AI 应用实践中,开发者常常会为了特定效果而进行工程优化,例如预设工作流程。然而当模型更新后,这些优化往往会失去价值甚至成为负担。Manus 团队采取了不同的策略:他们的工程优化主要集中在增强模型的延伸能力上,如网页浏览、文件解压等基础功能。这些「手 “、” 脚 “、” 眼 “ 和 “ 记事本 “ 般的辅助设施,无论模型如何发展都是必需的。团队尽量避免为了具体任务效果而过度干预模型的 “ 大脑」决策过程。
这种设计思路在模型自主性和人工干预之间找到了平衡点。它保留了工作流机制,但让 AI 自主生成工作流而非人工预设,既保证了灵活性又维持了系统性。[10]
一切的工作为了让用户「看见」
在设计 AI Agent 系统时,一个核心原则是:当无法确保最终结果的绝对正确性时,必须尽可能透明地展示执行过程,并为用户提供干预的机会。这一理念源于 AI Agent 工作方式的本质特征。
AI Agent 通常需要协调多个子任务来完成复杂工作流程,然而由于大模型底层原理的限制、难以避免的幻觉问题以及上下文窗口的约束,每个子任务的执行都存在失败风险。以概率计算为例,假设单个子任务的成功率为 95%,一个包含 10 个依赖性子任务的工作流,其整体成功率将骤降至 59.9%。这意味着用户每尝试 3 次就可能遭遇 1 次失败,而实际场景中的任务复杂度往往远超这个简单模型。
这种技术特性决定了展示过程的重要性。许多用户对 DeepSeek R1 的惊艳体验并非来自最终结果,而是源于对其思考过程的观察。同样地,Manus 通过其 plan 机制,将 Agent 的任务规划完整呈现给用户。这种透明化设计不仅展示了 Agent 的工作计划,更揭示了其决策逻辑和执行策略,从而建立起用户对系统的理解和信任。
Three More Things
快行动

回顾「快行动」项目的发展历程,我们可以发现它已经具备了通用 AI Agent 的雏形。从架构图和工作流程图来看,该项目采用了任务分解、多 Agent 协作和结果汇总的完整流程,这与现代 AI Agent 系统的设计理念高度吻合。虽然当时的技术条件有限,但这种架构设计已经展现出对未来 AI 工作方式的预见性。

是不是有那味道了。
MCP
关于 Manus 是否采用 MCP 技术的问题,创始人明确表示项目立项时间早于 MCP 技术的出现,因此目前尚未整合该技术。
下一篇我们看下 MCP 是什么?
其实,MCP 是比较符合我对未来的通用 AGI 的演进之路的。
去年 AI 大赛之后,我认为「快行动」、Manus 这一类的产品解决的是旧世界的产品设计不兼容新世界 AI 入口的问题。 [未来设计趋势应该由于用户到 Agent 的转变](https://blog.naaln.com/2025/03/MCP/#One More Thing)
比如让这些传统的产品为 AI 建立通用的入口,比如 高德地图 MCP,未来应该有淘宝 MCP、大众点评 MCP。
CUA
OpenAI 在 Manus 发布后推出的 CUA(Computer Using Agent) 技术同样值得关注。
A research preview of an agent that can use its own browser to perform tasks for you.
肝不动了,不研究了。
参考资料
- 1.Monica. (2024). Manus ↩
- 2.深度实机评测全球首个通用AI Agent ↩
- 3.Multi-agent 产品的改进空间 ↩
- 4.Manus 的护城河在哪里? ↩
- 5.I just simply asked Manus to give me the files at 「/opt/.manus/」 ↩
- 6.破解Manus工作原理:Claude Sonnet、29个工具、没用MCP、基于code-act 等技术 ↩
- 7.Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku Anthropic ↩
- 8.完整复盘:Manus 是怎么诞生的? ↩
- 9.Manus,为何是他们做出来了? ↩
- 10.屏蔽噪音,Manus 给我的 3 个启发 ↩