主流推荐的各种策略
我们平常在形形色色的应用上都会被推荐各种内容,我现在每天听歌都是只听推荐音乐,举几个栗子,除了听歌的时候有推荐音乐,还有看视频有推荐视频,看新闻有推荐新闻,买东西有推荐商品,基本上推荐这种功能我们都已经习以为常了。
最近做了一个和内容有关的产品,开始关心各种推荐机制是怎么实现的,基本上我把主要的推荐方式列为了以下几种:
- 基于热度的算法
- 协同过滤算法
- 基于内容的算法
- 基于模型的算法
1.基于热度的算法
第一种方式比较容易理解,例如微博的热搜、音乐视频应用的排行榜、电商的各种排行等等,就是根据各种比较容易获取的数据来直接向用户推荐。
2.协同过滤算法
协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
意思是用户 A 对指环王感兴趣,同时对哈利波特感兴趣。而用户 B 对指环王感兴趣,我们就可以推断他可能对哈利波特也感兴趣。
这种算法不仅可以用在人身上,也可以用在物身上,比如不同物品/项目之间的对比。例如 A 对指环王感兴趣,也对哈利波特感兴趣,也对天下无贼感兴趣;
将指环王和哈利波特和天下无贼对比相似度后,发现指环王和哈利波特最相似;
于是预测对指环王感兴趣的人也会对哈利波特感兴趣。
对于用户感兴趣的数值获取可以有各种方式,最直观的比如评分。这里我们介绍一种常用的算法:余弦相似度。
余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中。相似性范围从 -1 到 1:-1 意味着两个向量指向的方向正好截然相反,1 表示它们的指向是完全相同的,0 通常表示它们之间是独立的,而在这之间的值则表示中间的相似性或相异性。
也就是说,角度越小,越相似。
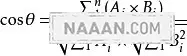
其中的 A、B 代表两个向量集合;
使用这个公式要注意,角度大小是不受向量长短影响的;遇到需要补全的向量我们一般用平均值来代替。
协同过滤算法也有它的缺点,主要是冷启动和稀疏性:
在项目冷启动的时候缺少对比数据;
在新用户进入时推荐质量差;
稀疏性问题;
3.基于内容/标签的算法
以一篇中文的新闻为例,一种方式是基于内容相似度进行推荐,另一种是基于用户进行推荐。
基于内容相似度来进行推荐,比如两篇文章,如何对比相似度呢?
首先先通过分词库/词典将两篇文章的词语分开,再将其中的「的」、「了」这类无意义词语去除,接下来把两篇文章的词语汇总成一个集合,分别统计两篇文章的词频;
举个栗子:
文章一:今天中国队战胜了巴西队,中国加油 |
分词结果:
文章一:今天/中国/队/战胜/了/巴西/队/中国/加油 |
统计结果:
文章一:今天(1)、中国(2)、队(2)、战胜(1)、巴西(1)、加油(1)、昨天(0)、打败(0)、回家(0) |
得到向量
A(1,2,2,1,1,1,0,0,0) |
是不是很眼熟,接下来是不是直接用上面的余弦相似度公式去计算就可以得到相似度了?
等等,一篇文章的复杂程度远比我那两句话要多多了,当把相似度的搜索范围扩大到很大的量的时候,会遇到一个问题,那就是不同的词作用可能并不相同,例如「世界杯」和「足球」两个词,明显「世界杯」的效果要比「足球」推荐效果好,「足球」出现的次数却要多于「世界杯」;所以这里还要给每个词加上词权,也就是权重,下面给大家介绍一种常用的加权方法,TF-IDF。
TF-IDF(term frequency–inverse document frequency)是非常常用的加权方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF 意思是词频 (Term Frequency),IDF 意思是逆文本频率指数 (Inverse Document Frequency)。
词频指的是词语在全部内容中出现的频率,频率越高表示词语在文章中的内容重要程度越高。
逆文本频率指数能够反映在所有参加对比的文章中,词语出现的频率;词语的这个值越大,它在所有文章中出现的频率越低,词语越重要,也就是物以稀为贵的意思。
计算方法如下:
TF=该词在该文章出现次数/该文章总词数 |
另一种是通过用户的标签和文章做相似度比较,直接用余弦相似度计算,这里就不多讲了。
4. 基于模型的算法
模型的算法就很多了,这里介绍一种预测模型,logistic 回归,是一种线性回归模型,也叫逻辑回归。
具体算法我就不讲了,比前面的几个都复杂得多,简单介绍下原理:
先知道下线性回归公式,目的是找到系数的最优值;
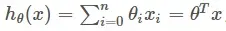
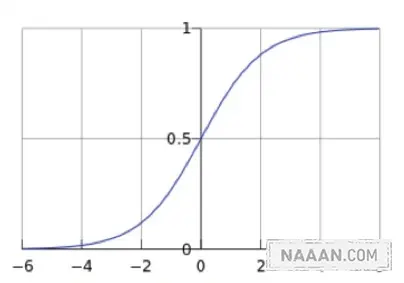
然后是对数几率函数(logistic function)作为激活函数对之前得到的系数进行预测,

第一步先找出所有自变量和因变量组成的向量;这里自变量可以是各种特征,比如性别、地域;因变量可以是各种程度判断,比如评分、评价数;
第二步把观察向量,将其拟合到一个函数上,得到该函数的系数,也就是公式里的 z;
第三步开始预测,通过对系数放入函数计算,大于 0.5 为成功,小于 0.5 为失败。
实际应用中的情况更加复杂,拟合得到的函数远比你想象的复杂。
结尾
任何算法都不是完美的,所以现在大家都在吹某条某音算法好的时候,也应该看到它的背后养了上千人的人工内容过滤团队,人工打标签还是最靠谱的办法之一;所以当你的产品没有足够数据和能力的时候,或许你还很难感受到算法的美妙。