闲谈流量统计(III)— 分析
捌、数据处理
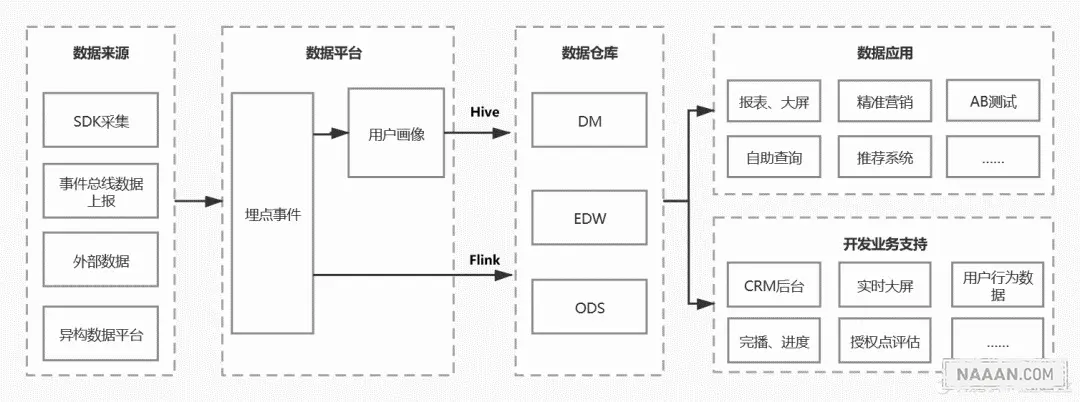
数据仓库设计
1. 脏数据清理
在数据采集阶段,会有很多的脏数据。这些数据有可能是用户恶意攻击,也有可能是在传输的阶段数据丢失,也有可能是服务处理产生。在数据加工的过程中就要做好这些数据地域工作。
一般,在数据入库之前就会核对数据的完整性,或者核对特定的格式、数据结构、加密字段等,这一步操作可以去除大部分的非针对性的恶意攻击。
还有一些针对性的恶意攻击,需要细致化的分析攻击的数据。可能会采取过滤 IP,过滤设备等手段进行数据清洗。
再者,后续可以继续根据数据排查刷量数据等、爬虫数据。这一些数据的在不同的场景口径可能会不一样,有一些企业或去除爬虫数据,有一些企业会默认少部分的爬虫行为,常常这一类的数据与业务结合,不会直接过滤。
2. 数据补全
由于采集阶段的数据比较的原始,一般企业会先做一层简单的数据汇总,比如在行为数据补充用户数据,简单的计算出部分缺失数据。
在一些分析产品中,也会补全上下游联路,或者前后页面的跳转关系,页面时长统计等计算。
有条件的企业还会补充IP库,画像库来进一步的丰富用户数据。
同时为了满足应用层的分析结果,数据也会进行一些轻度的聚会。
3. 应用层数据处理
这一环节基本就是面向应用的数据设计,大部分场景使用维度建模就可以满足。
镹、数据分析
1. 经典分析模型
数据分析的基本结构
- 有多少用户
- 用户在来的
- 用户是谁
- 用户来做了什么
- 用户给产品创造了什么价值
- 用户是怎么离开
2. 增长黑客模型
现在很多人提倡增长黑客,即 AARRR模型:
- Acquisition:获取用户
- Activation:提高活跃度
- Retention:提高留存率
- Revenue:获取收入
- Refer:自传播
3. 分析产品
流量分析产品
用户行为分析
数据大屏
同时还有很多产品把流量数据作为数据源,与业务数据解惑,做更加精细化的分析。
闲谈流量统计(IV)—— 实战| Why·Liam·Blog
The Why·Liam·Blog by WhyLiam is licensed under a Creative Commons BY-NC-ND 4.0 International License.
由WhyLiam创作并维护的Why·Liam·Blog采用创作共用保留署名-非商业-禁止演绎4.0国际许可证。
本文首发于Why·Liam·Blog (https://blog.naaln.com),版权所有,侵权必究。
本文永久链接:https://blog.naaln.com/2020/03/data-analytic-3/